Imperative learning (IL) is a self-supervised neuro-symbolic learning framework for robot autonomy.
A prototype of IL was first mentioned in the iSLAM paper, while it was then formally defined in this long article:
Imperative Learning: A Self-supervised Neuro-Symbolic Learning Framework for Robot Autonomy.
Chen Wang, Kaiyi Ji, Junyi Geng, Zhongqiang Ren, Taimeng Fu, Fan Yang, Yifan Guo, Haonan He, Xiangyu Chen, Zitong Zhan, Qiwei Du, Shaoshu Su, Bowen Li, Yuheng Qiu, Yi Du, Qihang Li, Yifan Yang, Xiao Lin, Zhipeng Zhao.
International Journal of Robotics Research (IJRR), 2025.
Unifying robot autonomy via neuro-symbolic learning
@article{wang2025imperative,
title = {Imperative Learning: A Self-supervised Neuro-Symbolic Learning Framework for Robot Autonomy},
author = {Wang, Chen and Ji, Kaiyi and Geng, Junyi and Ren, Zhongqiang and Fu, Taimeng and Yang, Fan and Guo, Yifan and He, Haonan and Chen, Xiangyu and Zhan, Zitong and Du, Qiwei and Su, Shaoshu and Li, Bowen and Qiu, Yuheng and Du, Yi and Li, Qihang and Yang, Yifan and Lin, Xiao and Zhao, Zhipeng},
journal = {International Journal of Robotics Research (IJRR)},
year = {2025},
url = {https://arxiv.org/abs/2406.16087},
code = {https://github.com/sair-lab/iSeries},
website = {https://sairlab.org/iseries},
cover = {/img/posts/2024-07-02-iSeries/il-cover.jpg},
addendum = {Unifying robot autonomy via neuro-symbolic learning}
}
Wang, Chen and Ji, Kaiyi and Geng, Junyi and Ren, Zhongqiang and Fu, Taimeng and Yang, Fan and Guo, Yifan and He, Haonan and Chen, Xiangyu and Zhan, Zitong and Du, Qiwei and Su, Shaoshu and Li, Bowen and Qiu, Yuheng and Du, Yi and Li, Qihang and Yang, Yifan and Lin, Xiao and Zhao, Zhipeng, "Imperative Learning: A Self-supervised Neuro-Symbolic Learning Framework for Robot Autonomy," International Journal of Robotics Research (IJRR), 2025.
This iSeries collects articles from the SAIR lab, named after a leading character “i” from “imperative learning”. In the iSeries collection, IL has been applied to various tasks including path planning, feature matching, and multi-robot routing, etc.
The list of iSeries articles
iA*: Imperative Learning-based A* Search for Path Planning.
Xiangyu Chen, Fan Yang, Chen Wang.
IEEE Robotics and Automation Letters (RA-L), vol. 10, no. 12, pp. 12987–12994, 2025.
Reducing 66% search area and 54% runtime via imperative learning
@article{chen2025iastar,
title = {{iA*}: Imperative Learning-based A* Search for Path Planning},
author = {Chen, Xiangyu and Yang, Fan and Wang, Chen},
journal = {IEEE Robotics and Automation Letters (RA-L)},
year = {2025},
volume = {10},
number = {12},
pages = {12987-12994},
url = {https://arxiv.org/abs/2403.15870},
code = {https://github.com/sair-lab/iAstar},
website = {https://sairlab.org/iastar/},
cover = {/img/posts/2024-10-28-iAstar/cover.gif},
addendum = {Reducing 66\% search area and 54\% runtime via imperative learning}
}
Chen, Xiangyu and Yang, Fan and Wang, Chen, "iA*: Imperative Learning-based A* Search for Path Planning," IEEE Robotics and Automation Letters (RA-L), 2025.
iWalker: Imperative Visual Planning for Walking Humanoid Robot.
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 2865–2872, 2025.
Best Workshop Paper Award; Enabling humanoid walking via self-supervised footstep planning
@inproceedings{lin2025iwalker,
title = {{iWalker}: Imperative Visual Planning for Walking Humanoid Robot},
author = {Lin, Xiao and Huang, Yuhao and Fu, Taimeng and Xiong, Xiaobin and Wang, Chen},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
pages = {2865--2872},
year = {2025},
url = {https://arxiv.org/abs/2409.18361},
video = {https://youtu.be/FPV74PznzTU},
website = {https://sairlab.org/iwalker},
cover = {/img/posts/2024-09-30-iwalker/thumbnail.gif},
addendum = {Best Workshop Paper Award; Enabling humanoid walking via self-supervised footstep planning}
}
Lin, Xiao and Huang, Yuhao and Fu, Taimeng and Xiong, Xiaobin and Wang, Chen, "iWalker: Imperative Visual Planning for Walking Humanoid Robot," IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025.
iKap: Kinematics-aware Planning with Imperative Learning.
IEEE International Conference on Robotics and Automation (ICRA), pp. 10164–10170, 2025.
First imperative learning planner that respects robot kinematics constraints
@inproceedings{li2025ikap,
title = {{iKap}: Kinematics-aware Planning with Imperative Learning},
author = {Li, Qihang and Chen, Zhuoqun and Zheng, Haoze and He, Haonan and Su, Shaoshu and Geng, Junyi and Wang, Chen},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
year = {2025},
pages = {10164--10170},
url = {https://arxiv.org/abs/2412.09496},
video = {https://youtu.be/7HPAMFbHc4U},
website = {https://sairlab.org/iKap},
cover = {/img/posts/2024-12-12-ikap/cover.gif},
addendum = {First imperative learning planner that respects robot kinematics constraints}
}
Li, Qihang and Chen, Zhuoqun and Zheng, Haoze and He, Haonan and Su, Shaoshu and Geng, Junyi and Wang, Chen, "iKap: Kinematics-aware Planning with Imperative Learning," IEEE International Conference on Robotics and Automation (ICRA), 2025.
European Conference on Computer Vision (ECCV), pp. 183–200, 2024.
A self-supervised feature learning approach pushes SOTA by 30% accuracy gain
@inproceedings{zhan2024imatching,
title = {{iMatching}: Imperative Correspondence Learning},
author = {Zhan, Zitong and Gao, Dasong and Lin, Yun-Jou and Xia, Youjie and Wang, Chen},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024},
pages = {183--200},
url = {https://arxiv.org/abs/2312.02141},
code = {https://github.com/sair-lab/iMatching},
website = {https://sairlab.org/iMatching},
cover = {/img/posts/2024-07-03-imatching/imatching.gif},
addendum = {A self-supervised feature learning approach pushes SOTA by 30\% accuracy gain}
}
Zhan, Zitong and Gao, Dasong and Lin, Yun-Jou and Xia, Youjie and Wang, Chen, "iMatching: Imperative Correspondence Learning," European Conference on Computer Vision (ECCV), 2024.
iMTSP: Solving Min-Max Multiple Traveling Salesman Problem with Imperative Learning.
Yifan Guo, Zhongqiang Ren, Chen Wang.
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 10245–10252, 2024.
A pioneer work on imperative learning with discrete optimization
@inproceedings{guo2024imtsp,
title = {{iMTSP}: Solving Min-Max Multiple Traveling Salesman Problem with Imperative Learning},
author = {Guo, Yifan and Ren, Zhongqiang and Wang, Chen},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year = {2024},
pages = {10245--10252},
url = {https://arxiv.org/abs/2405.00285},
code = {https://github.com/sair-lab/iMTSP},
video = {https://youtu.be/h0oflFcvPSc},
website = {https://sairlab.org/iMTSP},
cover = {/img/posts/2024-05-20-iMTSP/iMTSP.mp4},
addendum = {A pioneer work on imperative learning with discrete optimization}
}
Guo, Yifan and Ren, Zhongqiang and Wang, Chen, "iMTSP: Solving Min-Max Multiple Traveling Salesman Problem with Imperative Learning," IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024.
iSLAM: Imperative SLAM.
Taimeng Fu, Shaoshu Su, Yiren Lu, Chen Wang.
IEEE Robotics and Automation Letters (RA-L), vol. 9, no. 5, pp. 4607–4614, 2024.
Presented at ICRA 2025First to unify front-end odometry and back-end pose graph via reciprocal learning
@article{fu2024islam,
title = {{iSLAM}: Imperative {SLAM}},
author = {Fu, Taimeng and Su, Shaoshu and Lu, Yiren and Wang, Chen},
journal = {IEEE Robotics and Automation Letters (RA-L)},
year = {2024},
volume = {9},
number = {5},
pages = {4607--4614},
url = {https://arxiv.org/abs/2306.07894},
code = {https://github.com/sair-lab/iSLAM/},
video = {https://youtu.be/rtCvx0XCRno},
website = {https://sairlab.org/iSLAM},
cover = {/img/posts/2023-08-01-iSLAM/iSLAM.mp4},
addinfo = {Presented at ICRA 2025},
addendum = {First to unify front-end odometry and back-end pose graph via reciprocal learning}
}
Fu, Taimeng and Su, Shaoshu and Lu, Yiren and Wang, Chen, "iSLAM: Imperative SLAM," IEEE Robotics and Automation Letters (RA-L), 2024.
iPlanner: Imperative Path Planning.
Fan Yang, Chen Wang, Cesar Cadena, Marco Hutter.
Robotics: Science and Systems (RSS), 2023.
A pioneer work in visual planning using imperative learning
@inproceedings{yang2023iplanner,
author = {Yang, Fan and Wang, Chen and Cadena, Cesar and Hutter, Marco},
title = {{iPlanner}: Imperative Path Planning},
booktitle = {Robotics: Science and Systems (RSS)},
url = {https://arxiv.org/abs/2302.11434},
code = {https://github.com/sair-lab/iPlanner},
year = {2023},
website = {https://sairlab.org/iPlanner/},
cover = {/img/posts/2023-07-30-iPlanner/iplanner-cover.gif},
addendum = {A pioneer work in visual planning using imperative learning}
}
Yang, Fan and Wang, Chen and Cadena, Cesar and Hutter, Marco, "iPlanner: Imperative Path Planning," Robotics: Science and Systems (RSS), 2023.
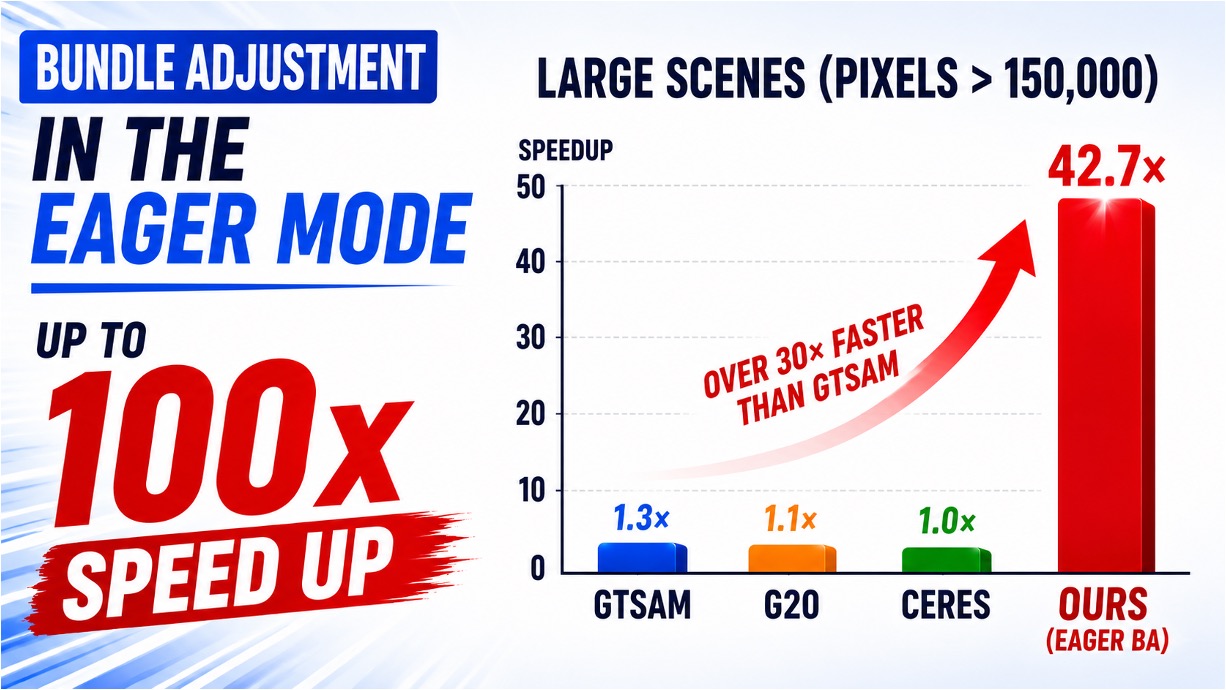
@article{zhan2026bundle,
title = {Bundle Adjustment in the Eager Mode},
author = {Zhan, Zitong and Xu, Huan and Fang, Zihang and Wei, Xinpeng and Hu, Yaoyu and Wang, Chen},
journal = {IEEE Transactions on Robotics (T-RO)},
year = {2026},
url = {https://arxiv.org/abs/2409.12190},
code = {https://github.com/sair-lab/bae},
website = {https://sairlab.org/bae/},
cover = {/img/posts/2026-03-24-bae/bae.gif},
video = {https://youtu.be/ONH7qYGRdFc},
addendum = {A GPU implementation achieving 20x speedup}
}
Zhan, Zitong and Xu, Huan and Fang, Zihang and Wei, Xinpeng and Hu, Yaoyu and Wang, Chen, "Bundle Adjustment in the Eager Mode," IEEE Transactions on Robotics (T-RO), 2026.
Resilient Odometry via Hierarchical Adaptation.
Shibo Zhao, Sifan Zhou, Yuchen Zhang, Ji Zhang, Chen Wang, Wenshan Wang, Sebastian Scherer.
Science Robotics, vol. 10, no. 109, 2025.
Top featured article in Science Robotics; Imperative learning enables all-weather resiliency; Exhibiting only 0.000067 (0.2m / 3km) drift without loop closure
@article{zhao2025resilient,
title = {Resilient Odometry via Hierarchical Adaptation},
author = {Zhao, Shibo and Zhou, Sifan and Zhang, Yuchen and Zhang, Ji and Wang, Chen and Wang, Wenshan and Scherer, Sebastian},
journal = {Science Robotics},
volume = {10},
number = {109},
year = {2025},
publisher = {American Association for the Advancement of Science},
url = {https://doi.org/10.1126/scirobotics.adv1818},
website = {https://superodometry.com/},
code = {https://github.com/superxslam/SuperOdom},
cover = {/img/pubs/SuperOdometry.mp4},
addendum = {Top featured article in Science Robotics; Imperative learning enables all-weather resiliency; Exhibiting only 0.000067 (0.2m / 3km) drift without loop closure}
}
Zhao, Shibo and Zhou, Sifan and Zhang, Yuchen and Zhang, Ji and Wang, Chen and Wang, Wenshan and Scherer, Sebastian, "Resilient Odometry via Hierarchical Adaptation," Science Robotics, 2025.
AnyNav: Visual Neuro-Symbolic Friction Learning for Off-road Navigation.
@article{fu2025anynav,
title = {{AnyNav}: Visual Neuro-Symbolic Friction Learning for Off-road Navigation},
author = {Fu, Taimeng and Zhan, Zitong and Zhao, Zhipeng and Su, Shaoshu and Lin, Xiao and Esfahani, Ehsan Tarkesh and Dantu, Karthik and Chowdhury, Souma and Wang, Chen},
journal = {arXiv preprint arXiv:2501.12654},
year = {2025},
url = {https://arxiv.org/abs/2501.12654},
website = {https://sairlab.org/anynav/},
cover = {/img/posts/2024-12-01-anynav/AnyNav.mp4},
addendum = {A self-supervised friction estimation framework}
}
Fu, Taimeng and Zhan, Zitong and Zhao, Zhipeng and Su, Shaoshu and Lin, Xiao and Esfahani, Ehsan Tarkesh and Dantu, Karthik and Chowdhury, Souma and Wang, Chen, "AnyNav: Visual Neuro-Symbolic Friction Learning for Off-road Navigation," arXiv preprint arXiv:2501.12654, 2025.
Neuro-Symbolic Learning for Long-Horizon Task Planning Under Complex Logical Constraints.
Qiwei Du, Zitong Zhan, Shaoshu Su, Bowen Li, Yi Du, Zhipeng Zhao, Taimeng Fu, Sebastian Scherer, Jiaoyang Li, Chen Wang.
arXiv preprint arXiv:2606.06877, 2026.
Reducing failures by 80% and eliminating exposure bias of neuro-symbolic task planning
@article{du2026iflax,
title = {Neuro-Symbolic Learning for Long-Horizon Task Planning Under Complex Logical Constraints},
author = {Du, Qiwei and Zhan, Zitong and Su, Shaoshu and Li, Bowen and Du, Yi and Zhao, Zhipeng and Fu, Taimeng and Scherer, Sebastian and Li, Jiaoyang and Wang, Chen},
journal = {arXiv preprint arXiv:2606.06877},
year = {2026},
url = {https://arxiv.org/abs/2606.06877},
website = {https://sairlab.org/iflax/},
video = {https://youtu.be/aRkq4TXYEhM},
cover = {/img/posts/2026-06-08-iflax/iflax_cover_video.mp4},
addendum = {Reducing failures by 80\% and eliminating exposure bias of neuro-symbolic task planning}
}
Du, Qiwei and Zhan, Zitong and Su, Shaoshu and Li, Bowen and Du, Yi and Zhao, Zhipeng and Fu, Taimeng and Scherer, Sebastian and Li, Jiaoyang and Wang, Chen, "Neuro-Symbolic Learning for Long-Horizon Task Planning Under Complex Logical Constraints," arXiv preprint arXiv:2606.06877, 2026.
This blog will briefly explain IL in a high-level perspective, as the reader may find more in-depth explanation in the paper.
What is a unified framework for robot autonomy?
- Three Principles
The three principles of a unified framwork for robot autonomy.
Data-driven and Scalable: Self-Supervised
Different from computer vision or language models, labeling data for robotic tasks is often significantly more costly, as it typically requires specialized equipment rather than simple human annotations. To ensure the scalability of data-driven approaches in robot autonomy, the development of effective self-supervised learning frameworks is essential.
Generalizable and Interpretable: Neuro-Symbolic Learning with Physical and Logical Structure
Robotic tasks often involve underlying structured knowledge governed by both physical laws and logical relationships, such as kinematic and logical constraints, task preconditions, and safety rules. Neuro-Symbolic learning enables the system to make decisions that are easier to interpret, while also improving generalization to novel tasks and environments by leveraging prior knowledge about how the world works.
Modular and Global Optimal: End-to-end Trainable
A modular design reduces complexity by decomposing a system into independent yet interconnected components, making development, debugging, and interpretation more manageable. However, training neural and symbolic modules separately can lead to suboptimal integration, as errors may propagate and accumulate across components. Therefore, we expect a modular system to be end-to-end trainable, retaining the interpretability and flexibility of modular design, while enabling joint optimization across the entire pipeline.
Why do we need Imperative Leanring?
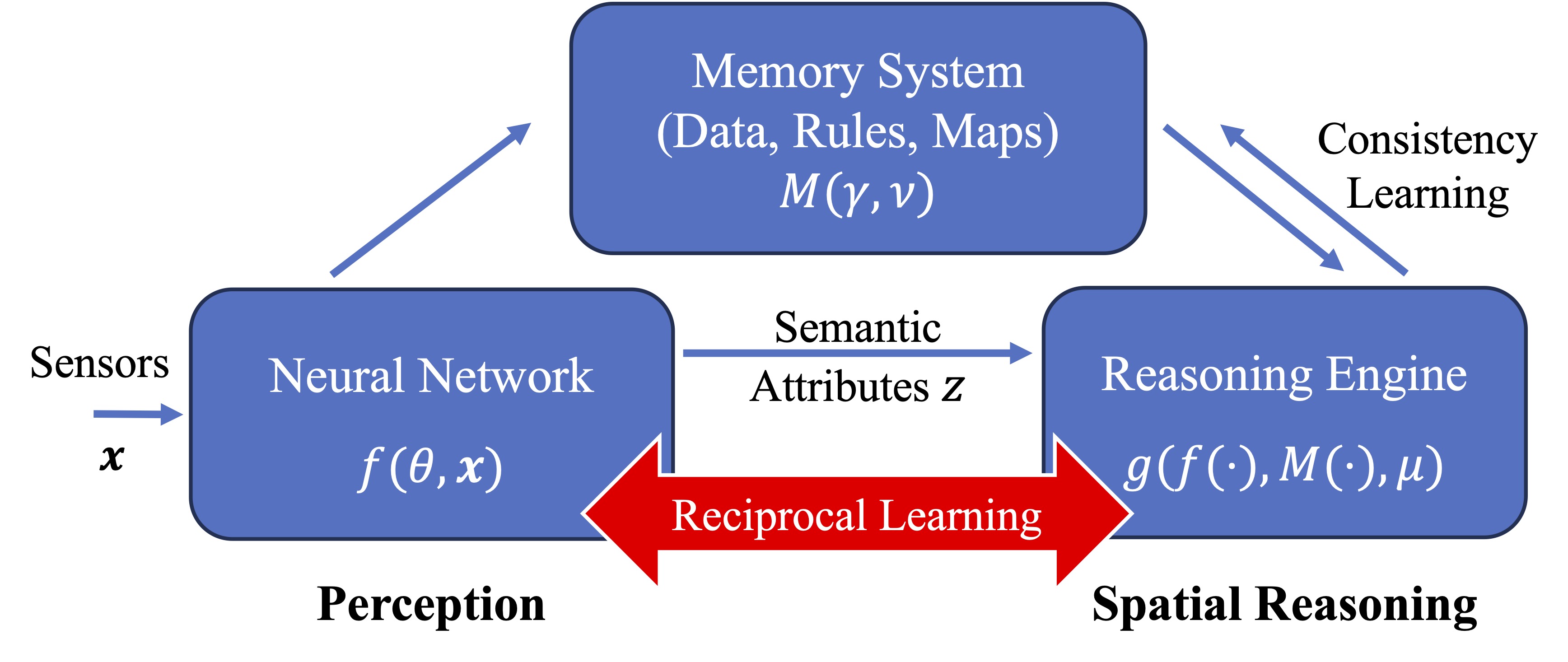
Imperative learning is a UNIFIED learning framework for robot autonomy following the three principles.
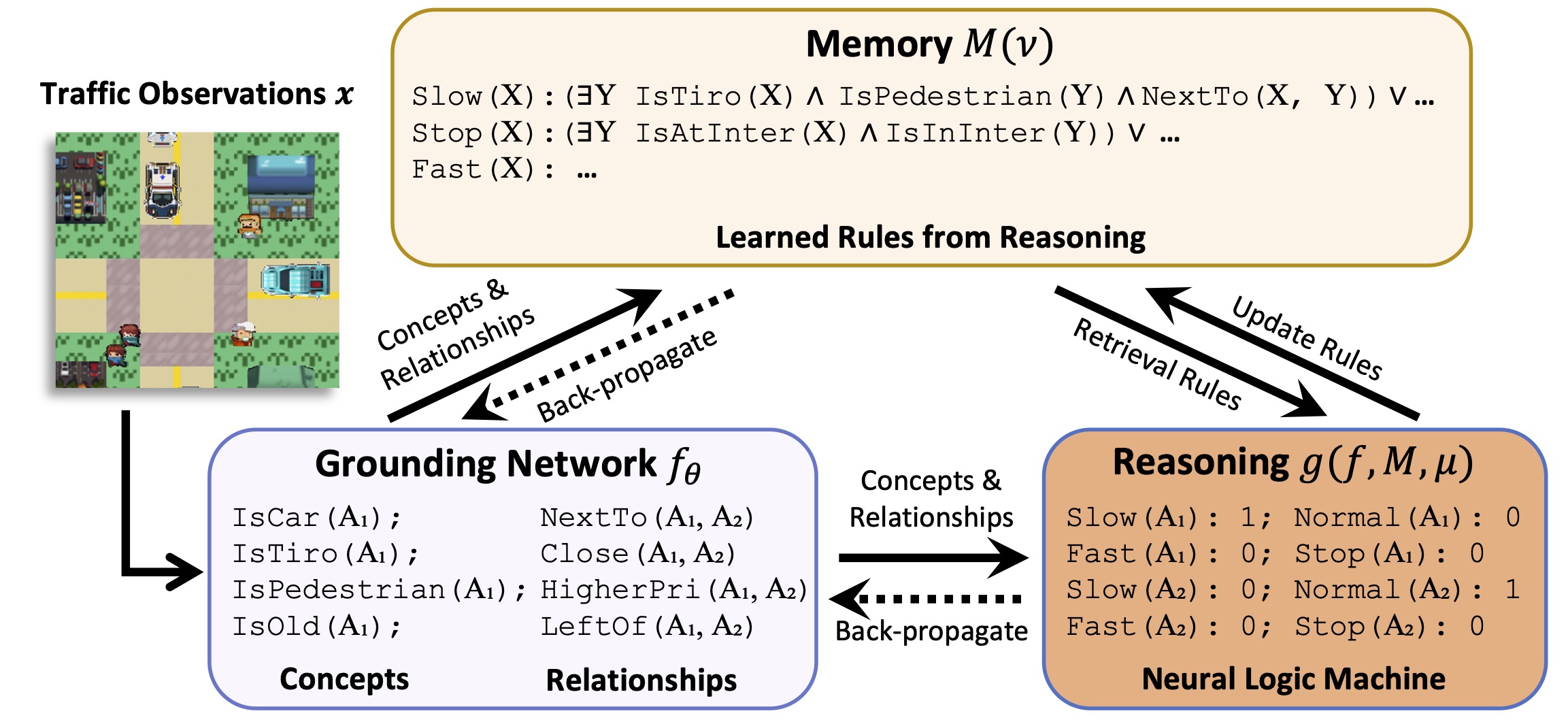
The imperative learning (IL) consists of three modules including a neural perceptual network, a symbolic reasoning engine, and a general memory system.
IL is formulated as a special bilevel optimization, enabling reciprocal learning and mutual correction among the three modules.
The framework of imperative learning.
Denote the neural system as \(\boldsymbol z = f({\boldsymbol{\theta}}, \boldsymbol{x})\), where \(\boldsymbol{x}\) represents the sensor measurements, \({\boldsymbol{\theta}}\) represents the perception-related learnable parameters, and \(\boldsymbol z\) represents the neural outputs such as semantic attributes; the reasoning engine as \(g(f, M, {\boldsymbol{\mu}})\) with reasoning-related parameters \({\boldsymbol{\mu}}\) and the memory system as \(M({\boldsymbol{\gamma}}, {\boldsymbol{\nu}})\), where \({\boldsymbol{\gamma}}\) is perception-related memory parameters and \({\boldsymbol{\nu}}\) is reasoning-related memory parameters. Therefore, imperative learning (IL) is formulated as a special BLO:
where \(\xi\) is a general constraint (either equality or inequality); \(U\) and \(L\) are the upper-level (UL) and lower-level (LL) cost functions; and \(\boldsymbol \psi \doteq [{\boldsymbol{\theta}}^\top, {\boldsymbol{\gamma}}^\top]^\top\) are stacked UL variables and \(\boldsymbol \phi \doteq [{\boldsymbol{\mu}}^\top, {\boldsymbol{\nu}}^\top]^\top\) are stacked LL variables, respectively.
Alternatively, \(U\) and \(L\) are also referred to as the neural cost and symbolic cost, respectively.
The term “imperative” is used to denote the passive nature of the learning process:
Once optimized, the neural system \(f\) in the UL cost will be driven to align with the LL reasoning engine \(g\)
E.g., logical, physical, or geometrical reasoning process with constraint \(\xi\).
Therefore, IL can learn to generate logically, physically, or geometrically feasible semantic attributes or predicates.
In some applications, \(\boldsymbol \psi\) and \(\boldsymbol \phi\) are also referred to as neuron-like and symbol-like parameters, respectively.
Self-supervised and End-to-end Trainable
Since many symbolic reasoning engines including geometric, physical, and logical reasoning, can be optimized or solved without providing labels.
For example, A\(^*\) search, geometrical reasoning such as bundle adjustment (BA), and physical reasoning like model predictive control (MPC) can be optimized without providing labels.
The IL framework leverages this phenomenon and jointly optimizes the three modules by bilevel optimization, which enforces the three modules to mutually correct each other.
Consequently, all three modules can be trained in a self-supervised and end-to-end manner by observing the world.
Although IL is designed for self-supervised learning, it can easily adapt to supervised or weakly supervised learning by involving labels either in UL or LL cost functions or both.
Overcoming the other Challenges.
The symbolic module offers better Interpretability and Generalization Ability due to its explainable design.
The Optimality is brought by bilevel optimization, compared to separately training the neural and symbolic modules.
Optimization Challenge
The solution to IL mainly involves solving the UL parameters \({\boldsymbol{\theta}}\) and \({\boldsymbol{\gamma}}\) and the LL parameters \({\boldsymbol{\mu}}\) and \({\boldsymbol{\nu}}\).
Intuitively, the UL parameters which are often neuron-like weights can be updated with the gradients of the UL cost $U$:
Since \(U\), \(L\), \(M\), \(g\), and \(f\) are often well defined, the challenge is to compute the derivative of lower-level (symbol-like) parameters w.r.t the upper-level (neuron-like) parameters, \(\color{blue}\frac{\partial \boldsymbol \phi^*}{\partial \boldsymbol \psi}\), which takes the form:
There are generally two ways to compute it, i.e., unrolled differentiation and implicit differentiation. See paper for more details.
Since \(\boldsymbol \psi \doteq [{\boldsymbol{\theta}}^\top, {\boldsymbol{\gamma}}^\top]^\top\) are LL parameters, the solution depends on the specific LL tasks.
Applications and Examples
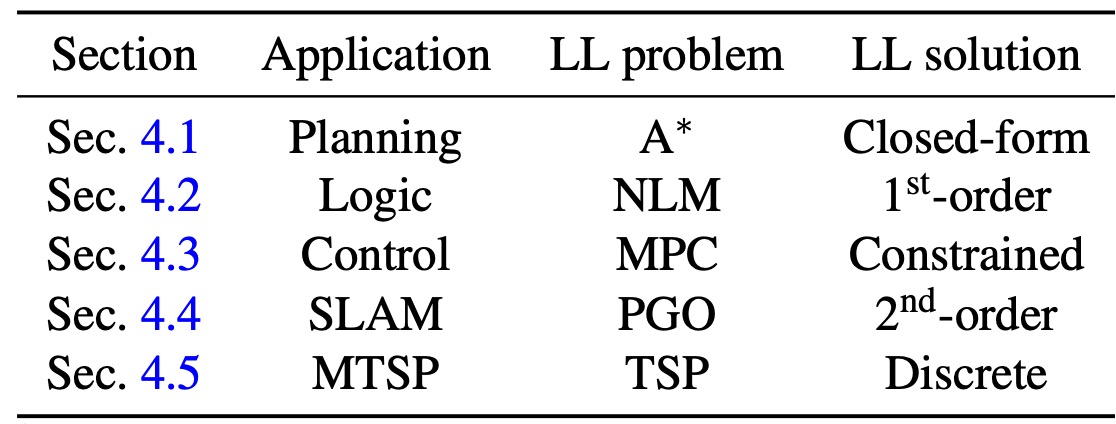
The paper provides five distinct examples covering the different cases of LL tasks.
The five distinct examples and their LL optimization methods.
Path Planning
In the case of LL tasks have closed-form solutions, we provide examples in both global and local path planning.
Global Path Planning
iA*: Imperative Learning-based A* Search for Path Planning.
Xiangyu Chen, Fan Yang, Chen Wang.
IEEE Robotics and Automation Letters (RA-L), vol. 10, no. 12, pp. 12987–12994, 2025.
Reducing 66% search area and 54% runtime via imperative learning
@article{chen2025iastar,
title = {{iA*}: Imperative Learning-based A* Search for Path Planning},
author = {Chen, Xiangyu and Yang, Fan and Wang, Chen},
journal = {IEEE Robotics and Automation Letters (RA-L)},
year = {2025},
volume = {10},
number = {12},
pages = {12987-12994},
url = {https://arxiv.org/abs/2403.15870},
code = {https://github.com/sair-lab/iAstar},
website = {https://sairlab.org/iastar/},
cover = {/img/posts/2024-10-28-iAstar/cover.gif},
addendum = {Reducing 66\% search area and 54\% runtime via imperative learning}
}
Chen, Xiangyu and Yang, Fan and Wang, Chen, "iA*: Imperative Learning-based A* Search for Path Planning," IEEE Robotics and Automation Letters (RA-L), 2025.
A\(^*\) is widely used due to its optimality, but often suffers low efficiency due to its large search space.
Therefore, we could leverage a neural module to predict a confined search space, leading to overall improved efficiency.
We take A\(^*\) as the symbolic reasoning engine and train the neural module in a self-supervised way based on IL.
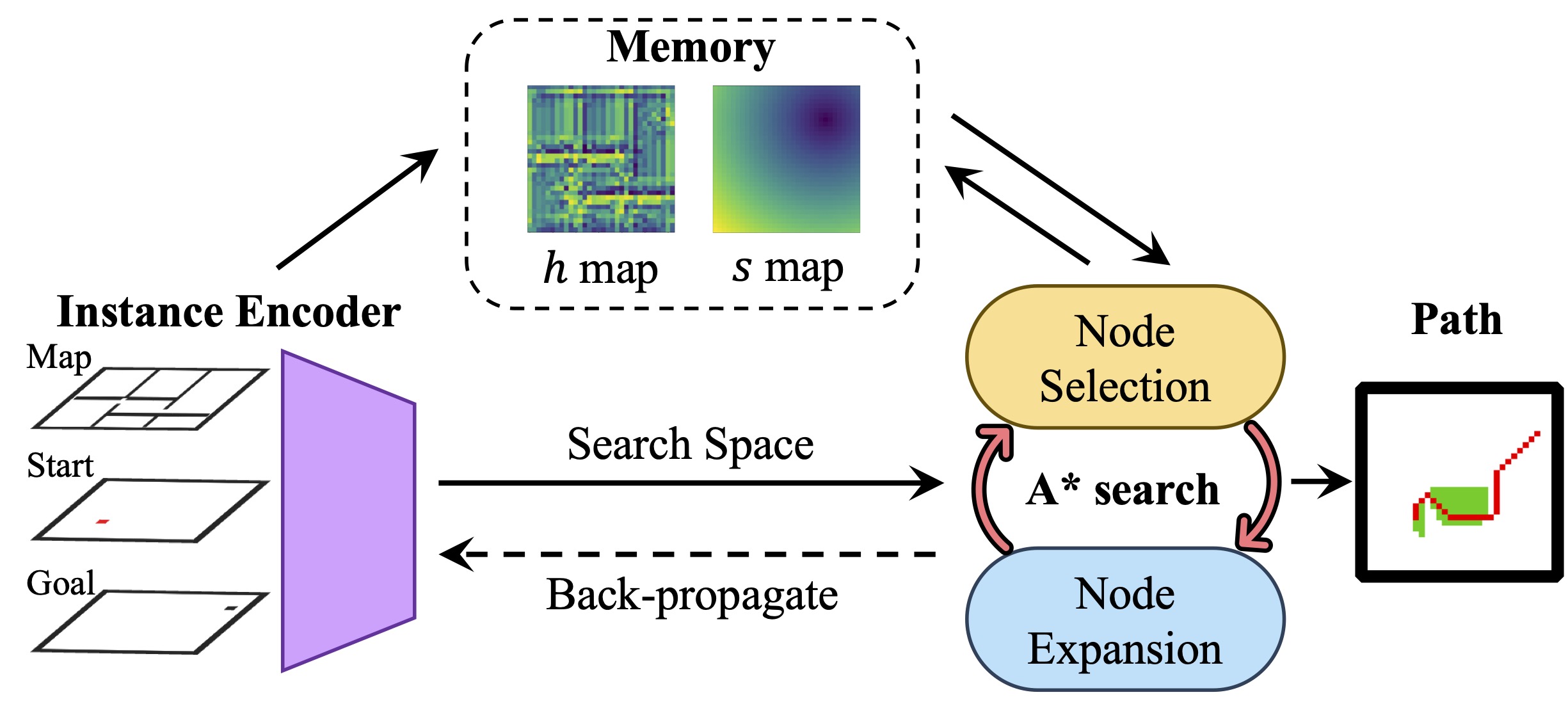
This results in a new framework, which is referred to as iA\(^*\).
The framework of iAstar.
Due to the confined search space and generalization ability from A*, iA\(^*\) outperforms both classic and other learning methods.
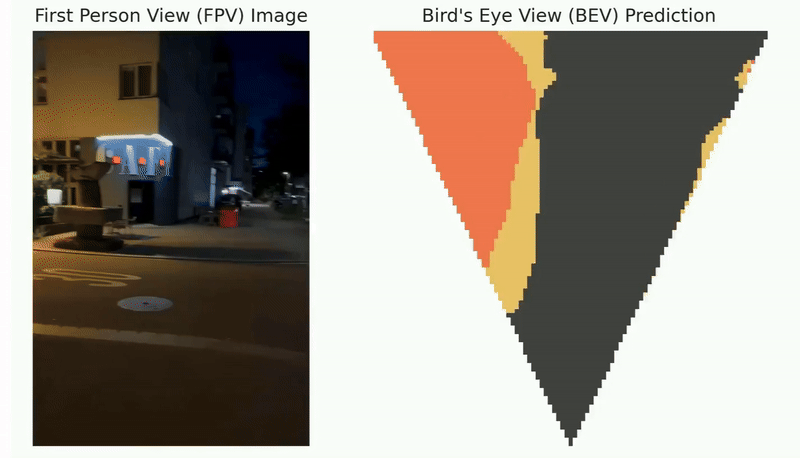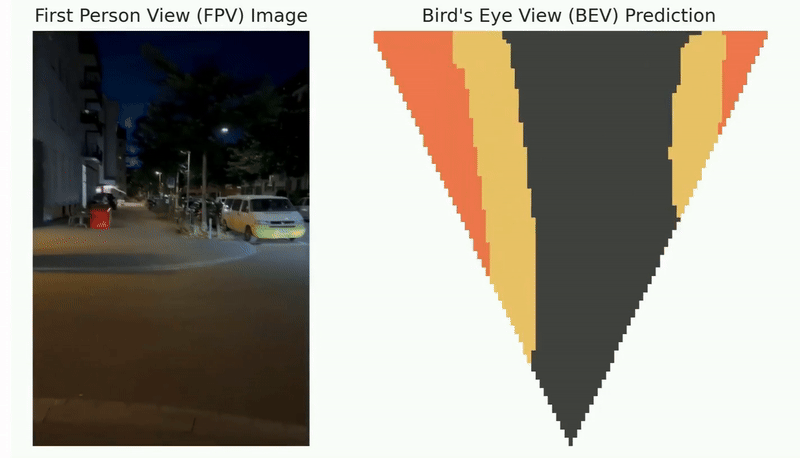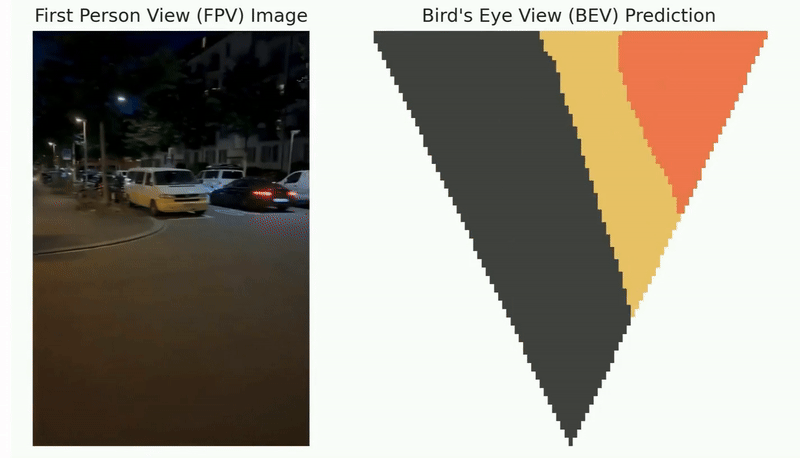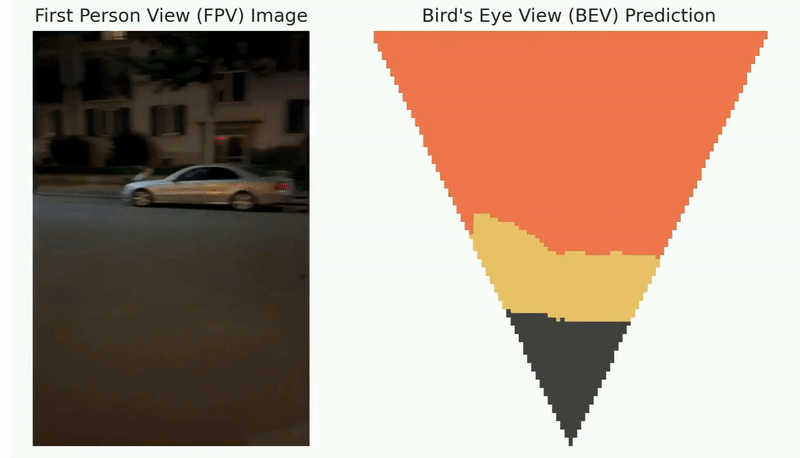
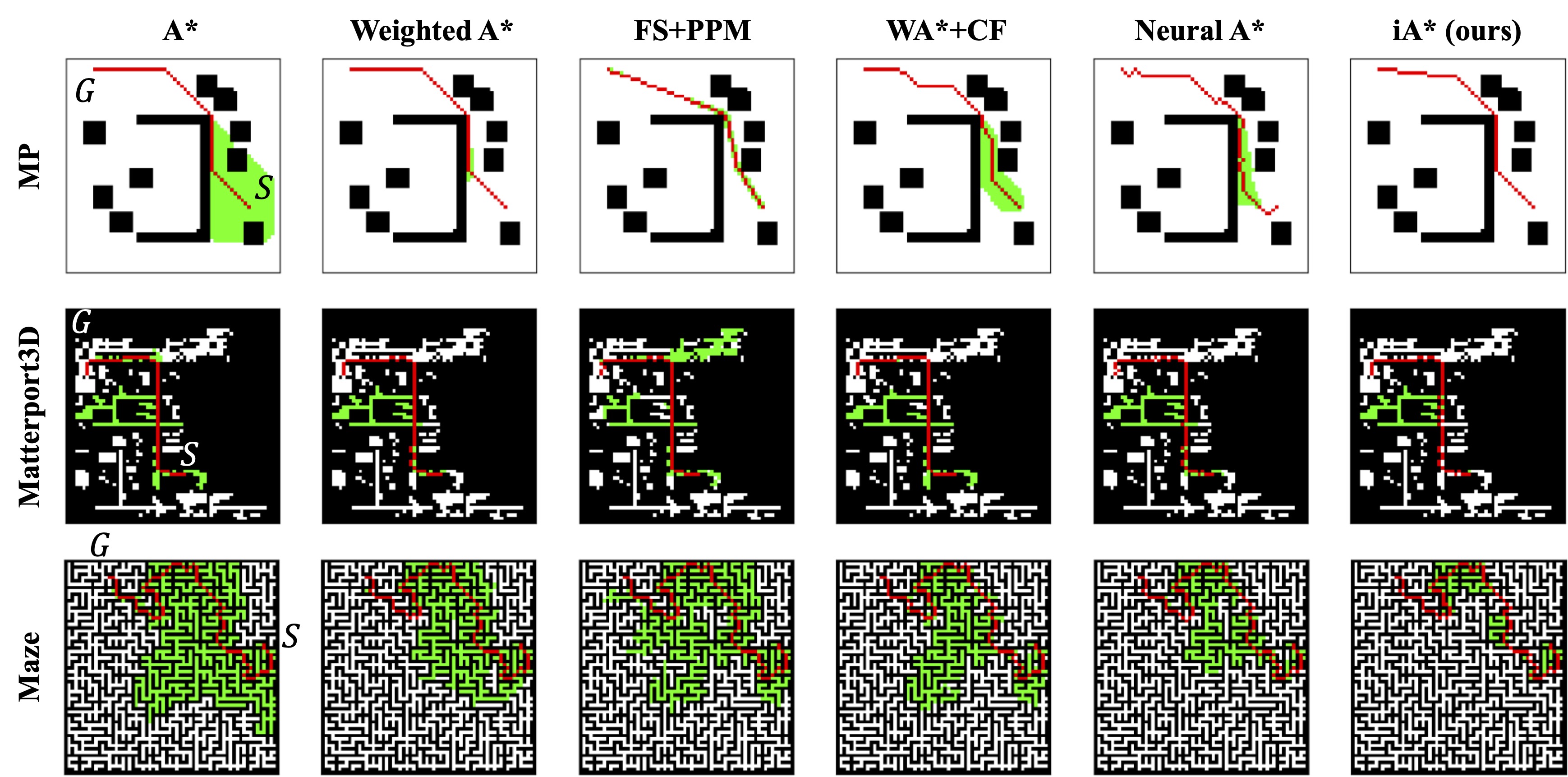
The following figure shows the qualitative results of path planning algorithms on datasets, including MP, Maze, and Matterport3D.
The qualitative results of path planning algorithms on three widely used datasets, including MP, Maze, and Matterport3D. The symbols S and G indicate the randomly selected start and goal positions. The optimal paths found by different path planning algorithms and their associated search space are indicated by red trajectories and green areas, respectively.
Local Path Planning
iPlanner: Imperative Path Planning.
Fan Yang, Chen Wang, Cesar Cadena, Marco Hutter.
Robotics: Science and Systems (RSS), 2023.
A pioneer work in visual planning using imperative learning
@inproceedings{yang2023iplanner,
author = {Yang, Fan and Wang, Chen and Cadena, Cesar and Hutter, Marco},
title = {{iPlanner}: Imperative Path Planning},
booktitle = {Robotics: Science and Systems (RSS)},
url = {https://arxiv.org/abs/2302.11434},
code = {https://github.com/sair-lab/iPlanner},
year = {2023},
website = {https://sairlab.org/iPlanner/},
cover = {/img/posts/2023-07-30-iPlanner/iplanner-cover.gif},
addendum = {A pioneer work in visual planning using imperative learning}
}
Yang, Fan and Wang, Chen and Cadena, Cesar and Hutter, Marco, "iPlanner: Imperative Path Planning," Robotics: Science and Systems (RSS), 2023.
End-to-end local path planning has recently attracted considerable interest, particularly for its potential to enable efficient inference.
Reinforcement learning-based methods often suffer from sample inefficiency and difficulties in directly processing depth images.
Imitation learning-based methods rely heavily on the availability and quality of labeled trajectories.
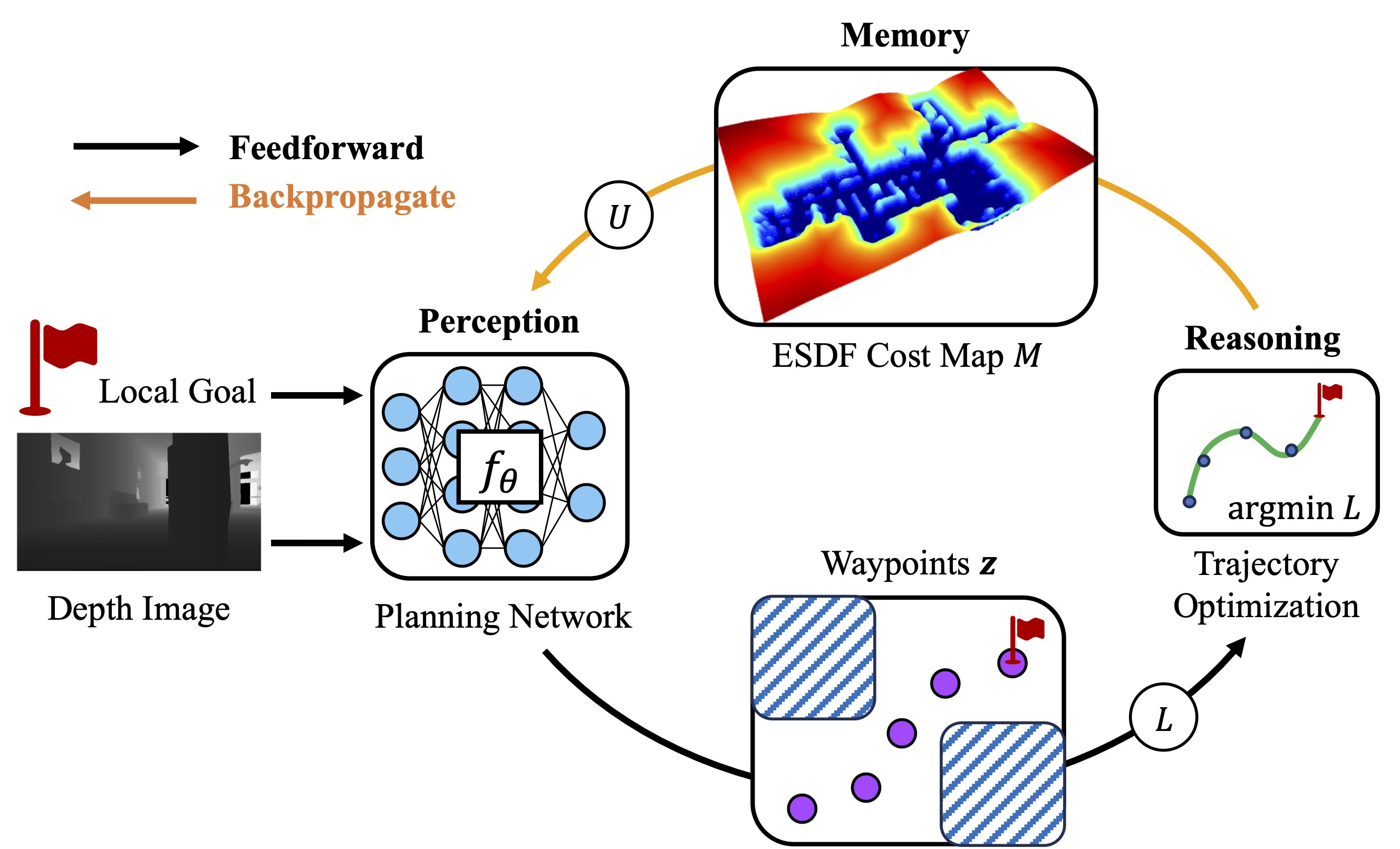
To solve those problems, we leverage a neural module to predict sparse waypoints, leading to overall improved efficiency.
The waypoints are then interpolated using a trajectory optimization engine based on a cubic spline.
We use IL to train this new framework, which is referred to as iPlanner.
The framework of iPlanner.
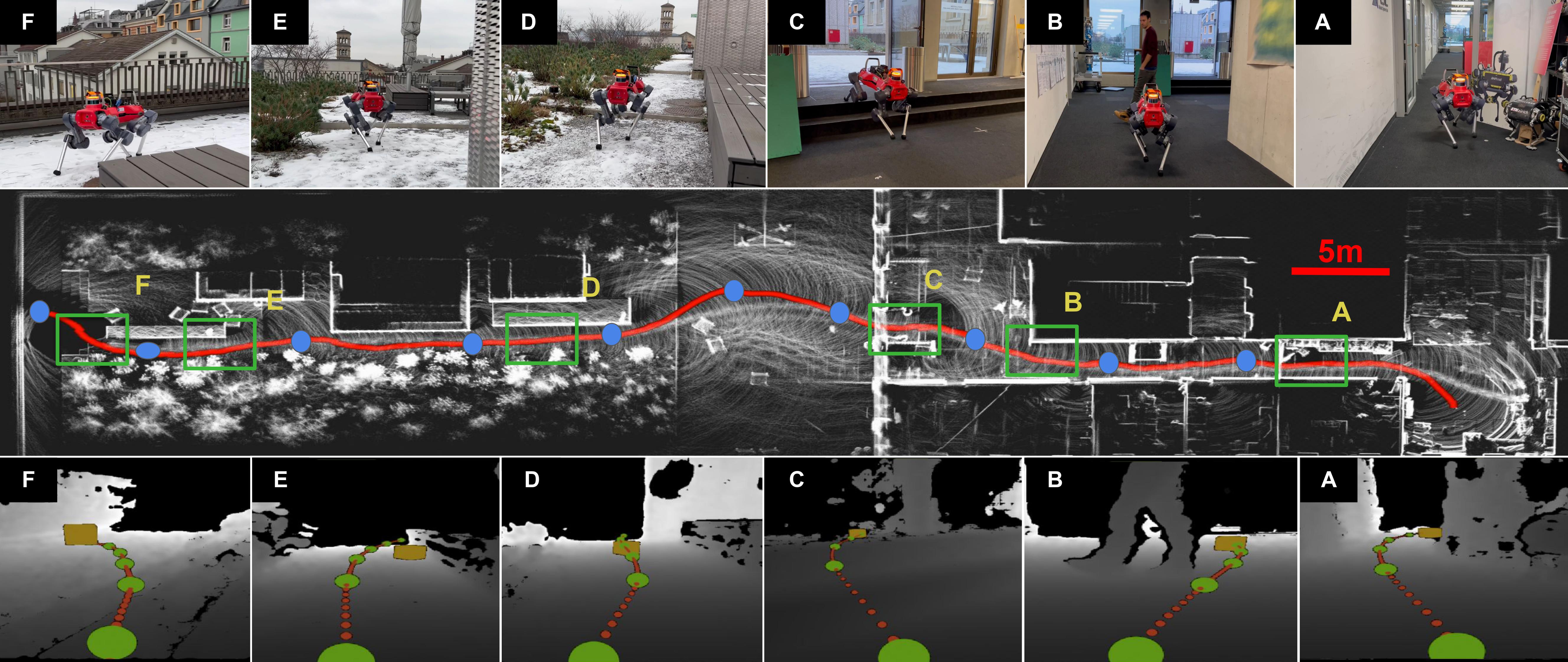
The following figure shows real-world experiment for local path planning using iPlanner with a legged robot.
Real-world experiment for local path planning using iPlanner with a legged robot. The red curve indicates the robot's trajectory from right to left, beginning inside a building and then navigating to the outdoors. The robot follows a series of waypoints (blue) and plans in different scenarios marked by green boxes including (A) passing through doorways, (B, D, E) circumventing both static and dynamic obstacles, and (B, F) ascending and descending stairs.
Logical Reasoning
In the case of the LL task needs first-order optimization, we provide an example in inductive logical reasoning.
Existing works only focus on toy examples, such as Visual Sudoku, and binary vector representations in BlocksWorld.
They cannot simultaneously perform grounding (high dimensional data) and rule induction.
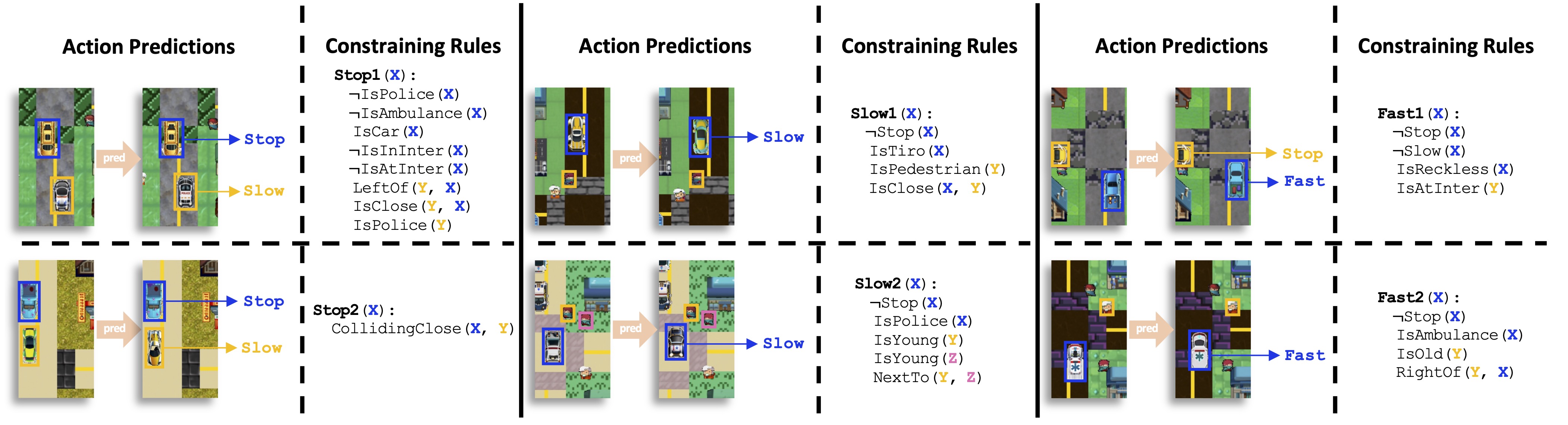
Based on IL, we use a neural network for concept and relationship prediction, and a neural logical machine (NLM) for rule induction.
We denote this new framework as iLogic.
The framework of iLogic.
In the following figure, iLogic conducts rule induction with perceived groundings and the constraining rules exhibited on the right side and finally gets the accurate action prediction exhibited on the left side.
The examples of learned rules using iLogic.
Optimal Control
A Self-Supervised Learning Approach with Differentiable Optimization for UAV Trajectory Planning.
IEEE International Conference on Robotics and Automation (ICRA), 2026.
@inproceedings{jiang2025self,
title = {A Self-Supervised Learning Approach with Differentiable Optimization for UAV Trajectory Planning},
author = {Jiang, Yufei and Zhan, Yuanzhu and Gupta, Harsh Vardhan and Borde, Chinmay and Geng, Junyi},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
url = {https://arxiv.org/abs/2504.04289},
year = {2026},
organization = {IEEE},
cover = {/img/pubs/iUAV.jpg}
}
Jiang, Yufei and Zhan, Yuanzhu and Gupta, Harsh Vardhan and Borde, Chinmay and Geng, Junyi, "A Self-Supervised Learning Approach with Differentiable Optimization for UAV Trajectory Planning," IEEE International Conference on Robotics and Automation (ICRA), 2026.
Imperative MPC: An End-to-End Self-Supervised Learning with Differentiable MPC for UAV Attitude Control.
Haonan He, Yuheng Qiu, Junyi Geng.
Annual Learning for Dynamics & Control Conference (L4DC), vol. 283, pp. 1140–1153, 2025.
@inproceedings{he2025imperative,
title = {Imperative MPC: An End-to-End Self-Supervised Learning with Differentiable MPC for UAV Attitude Control},
author = {He, Haonan and Qiu, Yuheng and Geng, Junyi},
booktitle = {Annual Learning for Dynamics \& Control Conference (L4DC)},
pages = {1140--1153},
year = {2025},
editor = {Ozay, Necmiye and Balzano, Laura and Panagou, Dimitra and Abate, Alessandro},
volume = {283},
series = {Proceedings of Machine Learning Research},
month = {04--06 Jun},
publisher = {PMLR},
pdf = {https://raw.githubusercontent.com/mlresearch/v283/main/assets/he25a/he25a.pdf},
url = {https://proceedings.mlr.press/v283/he25a.html},
cover = {/img/posts/2024-07-02-iSeries/iMPC.jpg}
}
He, Haonan and Qiu, Yuheng and Geng, Junyi, "Imperative MPC: An End-to-End Self-Supervised Learning with Differentiable MPC for UAV Attitude Control," Annual Learning for Dynamics & Control Conference (L4DC), 2025.
In the case of the LL task needs constrained optimization, we provide an example of UAV attitude control based on IMU.
Differentiable model predictive control (MPC) to combine the physics-based modeling with data-driven methods, enabling learning dynamic models and control policies in an end-to-end manner.
However, many prior studies depend on expert demonstrations or labeled data for supervised learning.
They often suffer from challenging conditions such as unseen environments and external disturbances.
Based on IL, we use a neural network for IMU denoising and predict the hyperparameters for MPC.
We denote this new framework as iMPC.
The framework of iMPC.
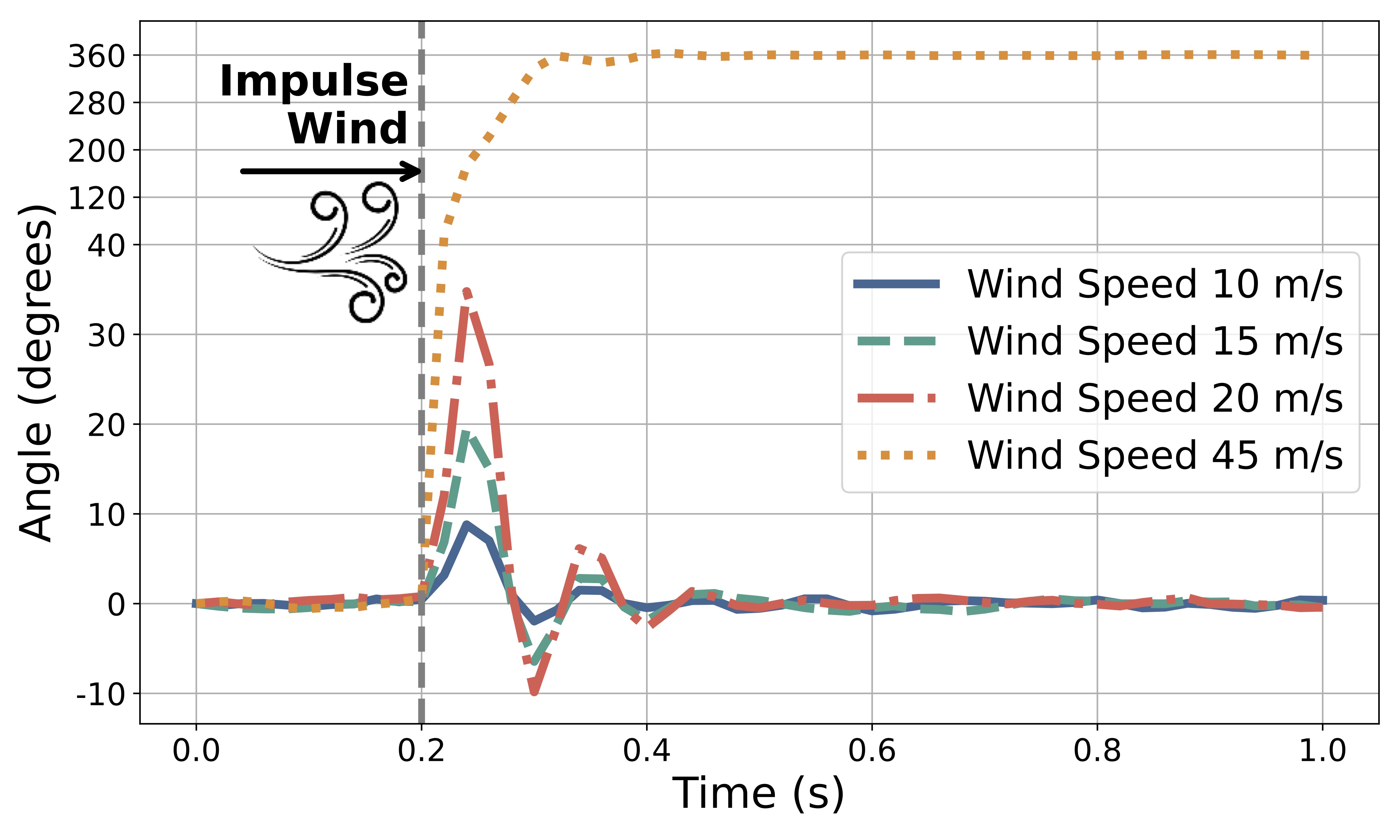
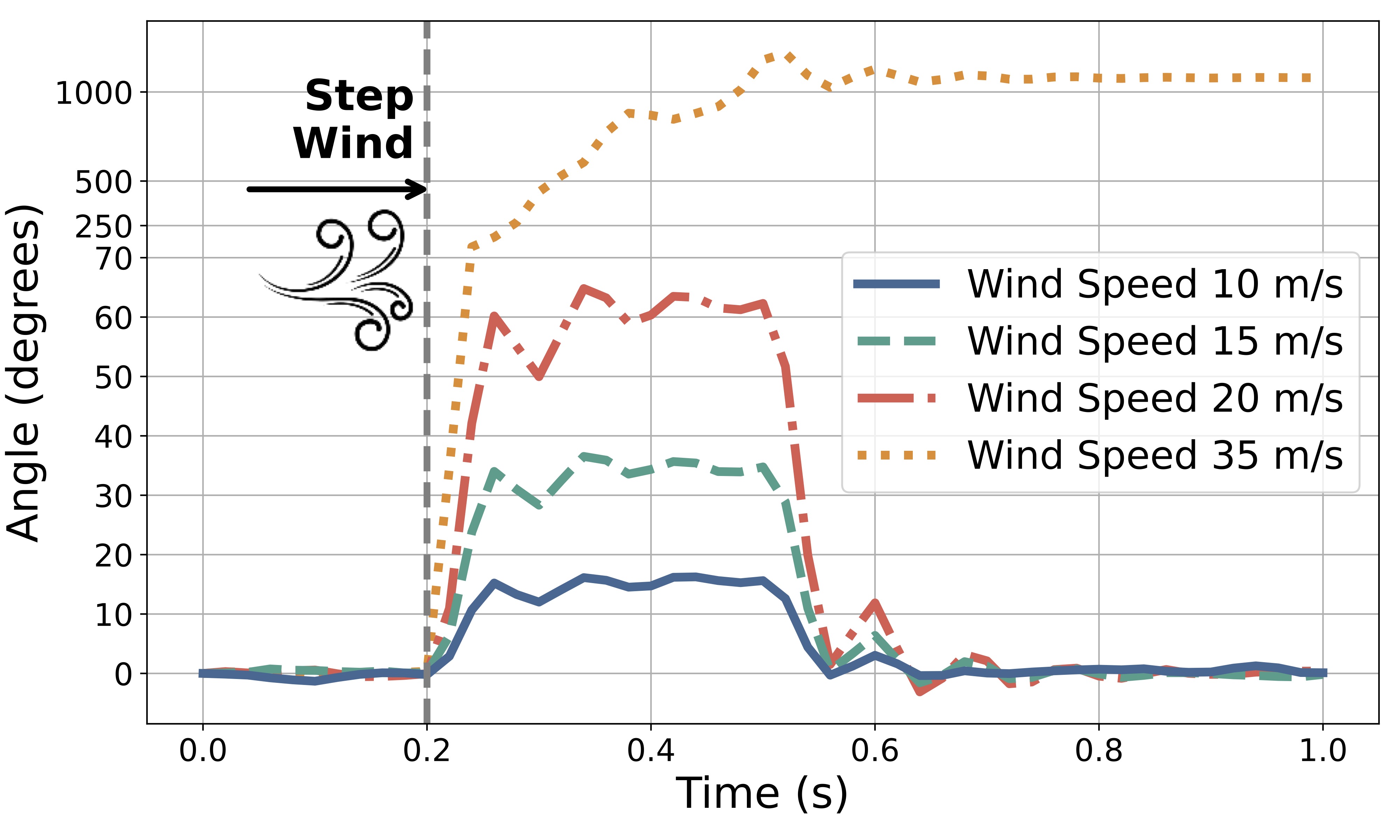
We evaluate the control performance under the wind disturbance to validate the robustness of the proposed approach.
Control performance of iMPC under different levels of wind disturbance.
Visual Odometry
iSLAM: Imperative SLAM.
Taimeng Fu, Shaoshu Su, Yiren Lu, Chen Wang.
IEEE Robotics and Automation Letters (RA-L), vol. 9, no. 5, pp. 4607–4614, 2024.
Presented at ICRA 2025First to unify front-end odometry and back-end pose graph via reciprocal learning
@article{fu2024islam,
title = {{iSLAM}: Imperative {SLAM}},
author = {Fu, Taimeng and Su, Shaoshu and Lu, Yiren and Wang, Chen},
journal = {IEEE Robotics and Automation Letters (RA-L)},
year = {2024},
volume = {9},
number = {5},
pages = {4607--4614},
url = {https://arxiv.org/abs/2306.07894},
code = {https://github.com/sair-lab/iSLAM/},
video = {https://youtu.be/rtCvx0XCRno},
website = {https://sairlab.org/iSLAM},
cover = {/img/posts/2023-08-01-iSLAM/iSLAM.mp4},
addinfo = {Presented at ICRA 2025},
addendum = {First to unify front-end odometry and back-end pose graph via reciprocal learning}
}
Fu, Taimeng and Su, Shaoshu and Lu, Yiren and Wang, Chen, "iSLAM: Imperative SLAM," IEEE Robotics and Automation Letters (RA-L), 2024.
In the case of the LL task needs second-order optimization, we provide an example of simultaneous localization and mapping (SLAM).
Existing SLAM systems only have single connection between the front-end odometry and back-end pose graph optimization.
This leads to sub-optimal solutions since there is no feedback from the back-end to the front-end.
We proposed to optimize the entire SLAM system based on IL, leading the self-supervised reciprocal correction between the front-end and the back-end.
We refer to this new framework as iSLAM.
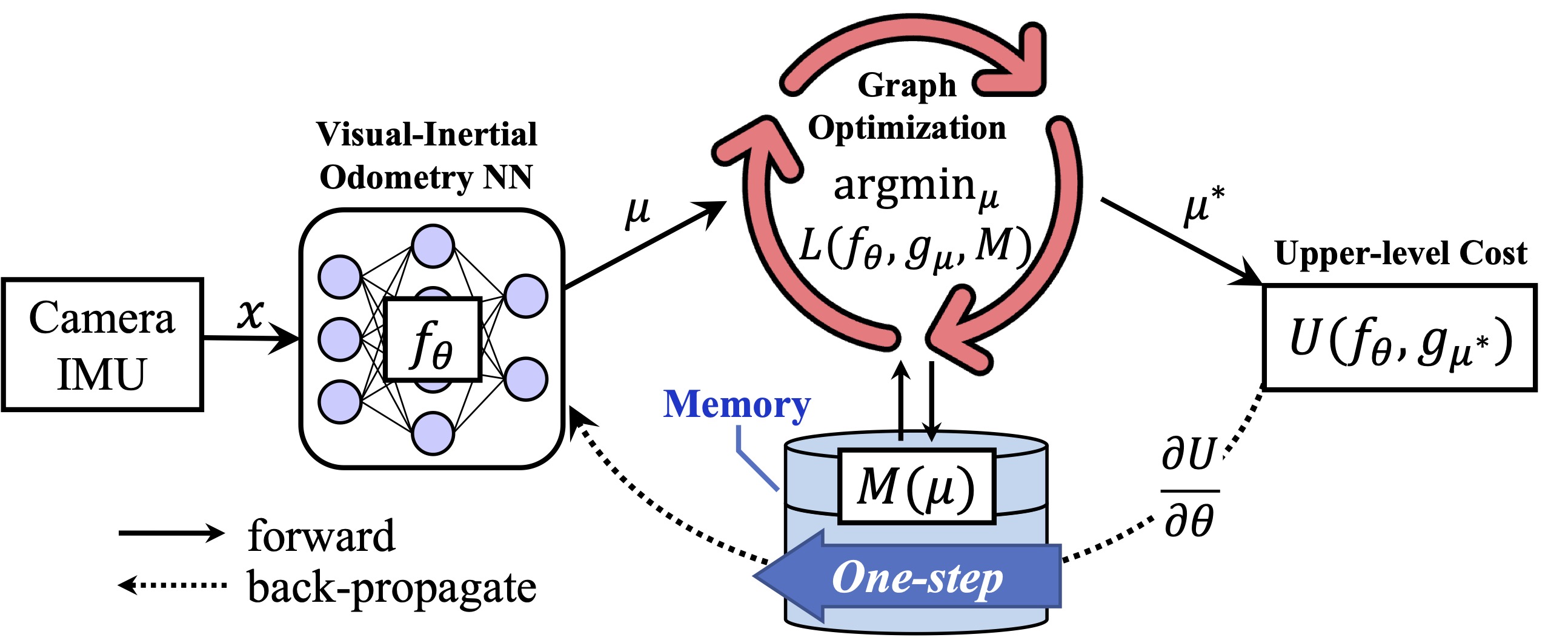
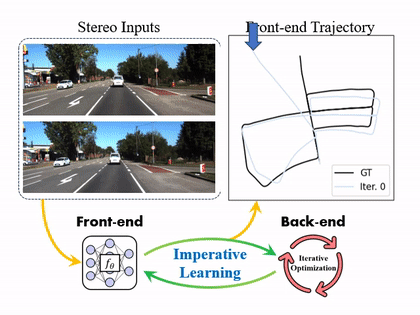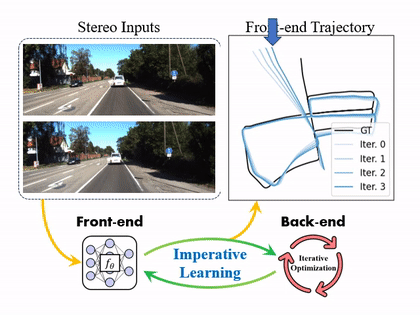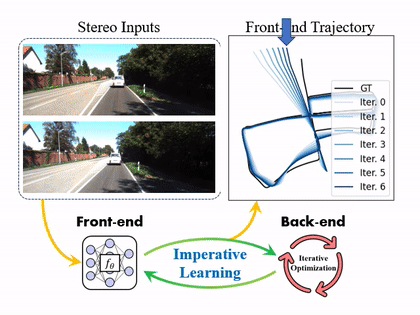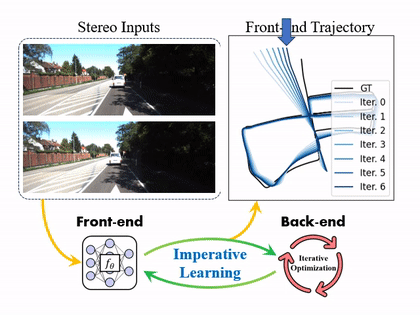
The framework of iSLAM. On the forward path, the odometry module (front-end) predicts the robot trajectory. The pose graph optimization (back-end) minimizes the LL cost in several iterations to get optimal poses. On the backward path, the UL cost is back-propagated through the map with a "one-step" strategy to update the network.
With more training iterations, the front-end odometry can be kept improving in the following figure.
The predicted trajectories from the front-end are improved concerning the number of imperative iterations in iSLAM.
Multi-agent Routing
iMTSP: Solving Min-Max Multiple Traveling Salesman Problem with Imperative Learning.
Yifan Guo, Zhongqiang Ren, Chen Wang.
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 10245–10252, 2024.
A pioneer work on imperative learning with discrete optimization
@inproceedings{guo2024imtsp,
title = {{iMTSP}: Solving Min-Max Multiple Traveling Salesman Problem with Imperative Learning},
author = {Guo, Yifan and Ren, Zhongqiang and Wang, Chen},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
year = {2024},
pages = {10245--10252},
url = {https://arxiv.org/abs/2405.00285},
code = {https://github.com/sair-lab/iMTSP},
video = {https://youtu.be/h0oflFcvPSc},
website = {https://sairlab.org/iMTSP},
cover = {/img/posts/2024-05-20-iMTSP/iMTSP.mp4},
addendum = {A pioneer work on imperative learning with discrete optimization}
}
Guo, Yifan and Ren, Zhongqiang and Wang, Chen, "iMTSP: Solving Min-Max Multiple Traveling Salesman Problem with Imperative Learning," IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2024.
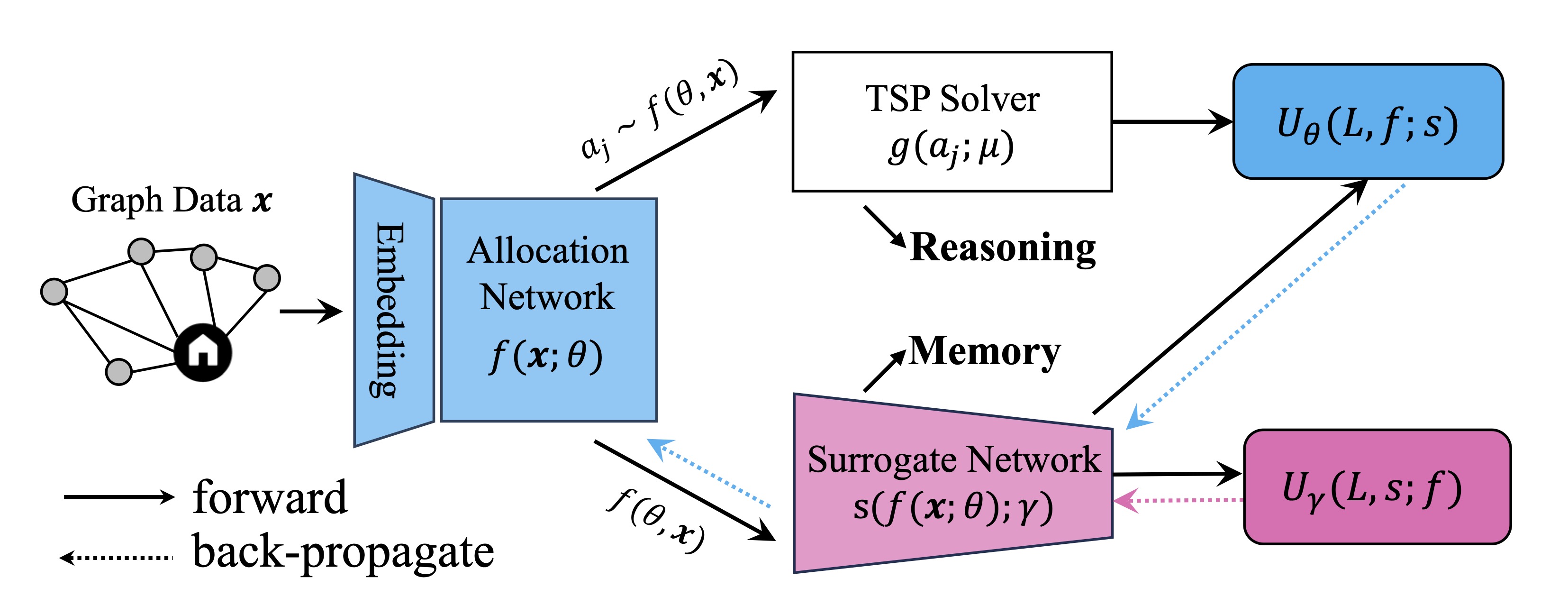
In the case of the LL task needs discrete optimization, we provide an example of multiple traveling salesman problem (MTSP).
Traditional methods for MTSP needs combinatorial optimization, which is discrete optimization in a very large space.
Classic MTSP solvers such as Google’s OR-Tools routing library meet difficulties for large-scale problems (>500 cities).
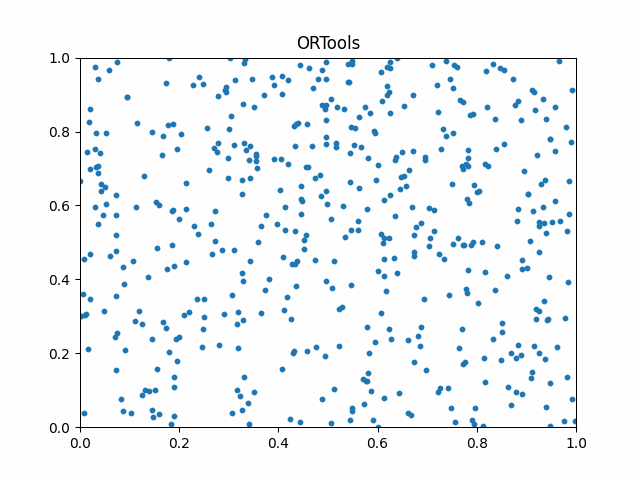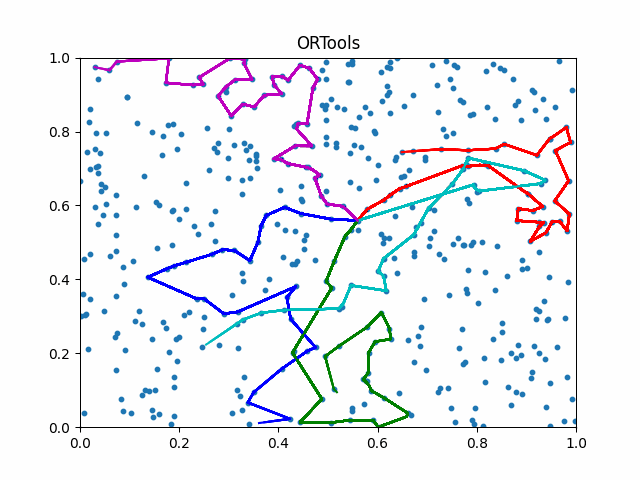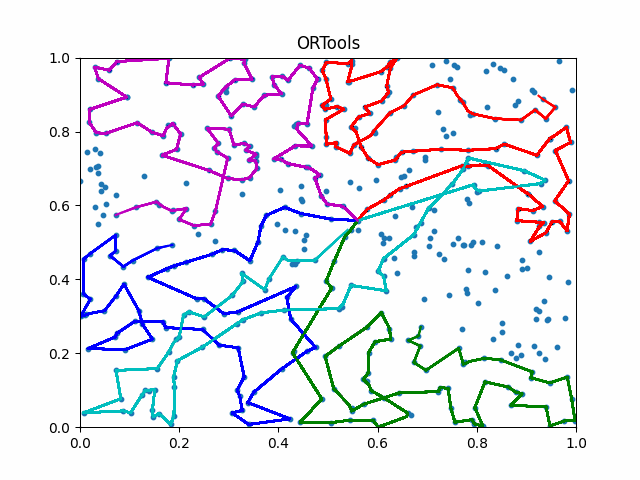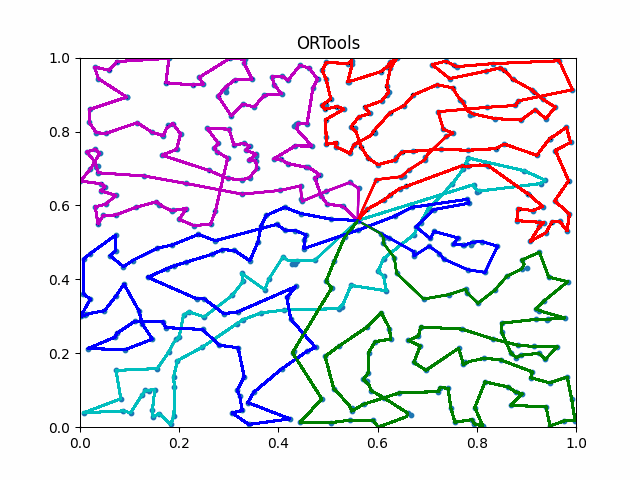
We introduce IL and use a neural network for city allocation to agents and then use single TSP solvers for divided smaller problems.
To compute the differentiation in discrete space, we introduce a surrogate network to estimate the gradient based on control variate.
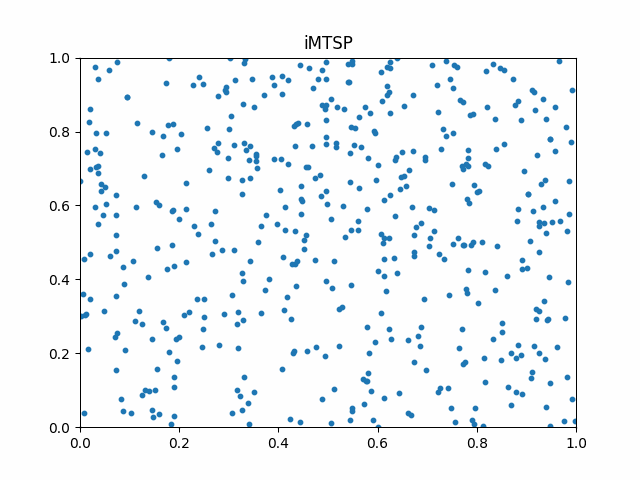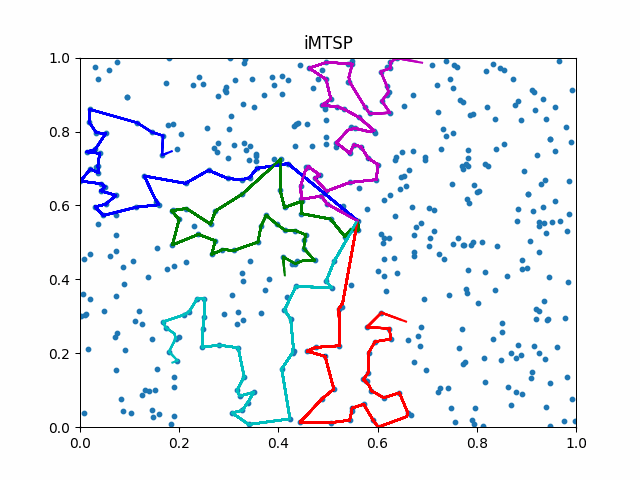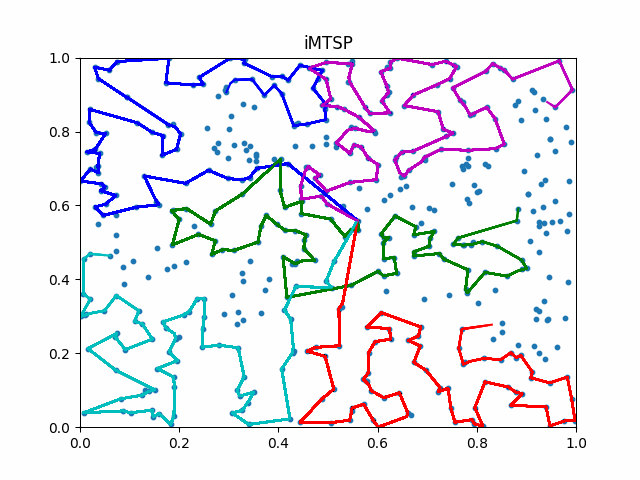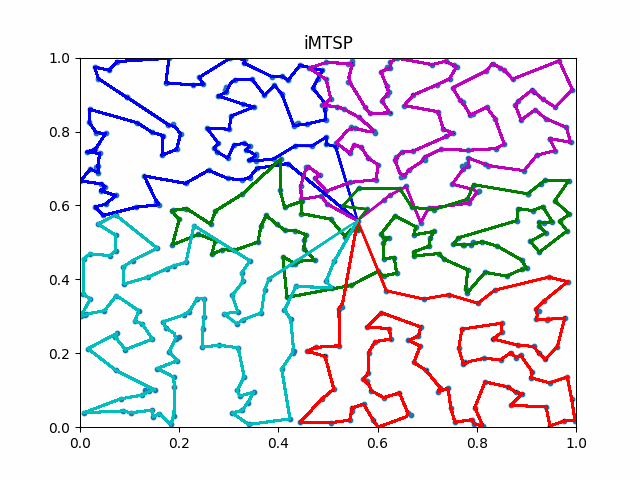
We refer this new framework as iMTSP.
The framework of iMTSP. A surrogate network is introduced as the memory in the IL framework, constructing a low-variance gradient for the allocation network through the non-differentiable and discrete TSP solvers.
Due to the generalization abilities of IL, iMTSP outperforms both classic solvers and RL-based methods.
Recommended External Publications
[1]
Joint Sparse Optical Flow Estimation and Keypoint Detection via Dual-task Imperative Learning.
IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), vol. 48, no. 3, pp. 2659–2675, 2026.
@article{liu2025joint,
title = {Joint Sparse Optical Flow Estimation and Keypoint Detection via Dual-task Imperative Learning},
author = {Liu, Qiang and Chen, Baojia and Hao, Zhiqiang and Li, Xinlong and Xiang, Leilei and Liu, Juan},
journal = {IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI)},
year = {2026},
volume = {48},
number = {3},
pages = {2659-2675},
doi = {10.1109/TPAMI.2025.3627192},
publisher = {IEEE}
}
Liu, Qiang and Chen, Baojia and Hao, Zhiqiang and Li, Xinlong and Xiang, Leilei and Liu, Juan, "Joint Sparse Optical Flow Estimation and Keypoint Detection via Dual-task Imperative Learning," IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), 2026.
[2]
A Self-Supervised Learning Approach with Differentiable Optimization for UAV Trajectory Planning.
IEEE International Conference on Robotics and Automation (ICRA), 2026.
@inproceedings{jiang2025self,
title = {A Self-Supervised Learning Approach with Differentiable Optimization for UAV Trajectory Planning},
author = {Jiang, Yufei and Zhan, Yuanzhu and Gupta, Harsh Vardhan and Borde, Chinmay and Geng, Junyi},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
url = {https://arxiv.org/abs/2504.04289},
year = {2026},
organization = {IEEE},
cover = {/img/pubs/iUAV.jpg}
}
Jiang, Yufei and Zhan, Yuanzhu and Gupta, Harsh Vardhan and Borde, Chinmay and Geng, Junyi, "A Self-Supervised Learning Approach with Differentiable Optimization for UAV Trajectory Planning," IEEE International Conference on Robotics and Automation (ICRA), 2026.
[3]
Imperative MPC: An End-to-End Self-Supervised Learning with Differentiable MPC for UAV Attitude Control.
Haonan He, Yuheng Qiu, Junyi Geng.
Annual Learning for Dynamics & Control Conference (L4DC), vol. 283, pp. 1140–1153, 2025.
@inproceedings{he2025imperative,
title = {Imperative MPC: An End-to-End Self-Supervised Learning with Differentiable MPC for UAV Attitude Control},
author = {He, Haonan and Qiu, Yuheng and Geng, Junyi},
booktitle = {Annual Learning for Dynamics \& Control Conference (L4DC)},
pages = {1140--1153},
year = {2025},
editor = {Ozay, Necmiye and Balzano, Laura and Panagou, Dimitra and Abate, Alessandro},
volume = {283},
series = {Proceedings of Machine Learning Research},
month = {04--06 Jun},
publisher = {PMLR},
pdf = {https://raw.githubusercontent.com/mlresearch/v283/main/assets/he25a/he25a.pdf},
url = {https://proceedings.mlr.press/v283/he25a.html},
cover = {/img/posts/2024-07-02-iSeries/iMPC.jpg}
}
He, Haonan and Qiu, Yuheng and Geng, Junyi, "Imperative MPC: An End-to-End Self-Supervised Learning with Differentiable MPC for UAV Attitude Control," Annual Learning for Dynamics & Control Conference (L4DC), 2025.
[4]
A Vision Transformer Framework for Real-Time Path Planning in Unknown Environments.
2025 9th International Conference on Vision, Image and Signal Processing (ICVISP), pp. 1–5, 2025.
@inproceedings{zheng2025vision,
title = {A Vision Transformer Framework for Real-Time Path Planning in Unknown Environments},
author = {Zheng, Yunjie and Chen, Weihuang and Zhang, Zhihao and Kong, Jintao and Chen, Liming and Gao, Zhiqiang and Sun, Hongbin},
booktitle = {2025 9th International Conference on Vision, Image and Signal Processing (ICVISP)},
pages = {1--5},
year = {2025},
organization = {IEEE}
}
Zheng, Yunjie and Chen, Weihuang and Zhang, Zhihao and Kong, Jintao and Chen, Liming and Gao, Zhiqiang and Sun, Hongbin, "A Vision Transformer Framework for Real-Time Path Planning in Unknown Environments," 2025 9th International Conference on Vision, Image and Signal Processing (ICVISP), 2025.
[5]
Viplanner: Visual semantic imperative learning for local navigation.
Pascal Roth, Julian Nubert, Fan Yang, Mayank Mittal, Marco Hutter.
2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 5243–5249, 2024.
@inproceedings{roth2024viplanner,
title = {Viplanner: Visual semantic imperative learning for local navigation},
author = {Roth, Pascal and Nubert, Julian and Yang, Fan and Mittal, Mayank and Hutter, Marco},
booktitle = {2024 IEEE International Conference on Robotics and Automation (ICRA)},
pages = {5243--5249},
year = {2024},
organization = {IEEE}
}
Roth, Pascal and Nubert, Julian and Yang, Fan and Mittal, Mayank and Hutter, Marco, "Viplanner: Visual semantic imperative learning for local navigation," 2024 IEEE International Conference on Robotics and Automation (ICRA), 2024.
 Imperative Learning: A Self-supervised Neuro-Symbolic Learning Framework for Robot Autonomy.International Journal of Robotics Research (IJRR), 2025.
Imperative Learning: A Self-supervised Neuro-Symbolic Learning Framework for Robot Autonomy.International Journal of Robotics Research (IJRR), 2025.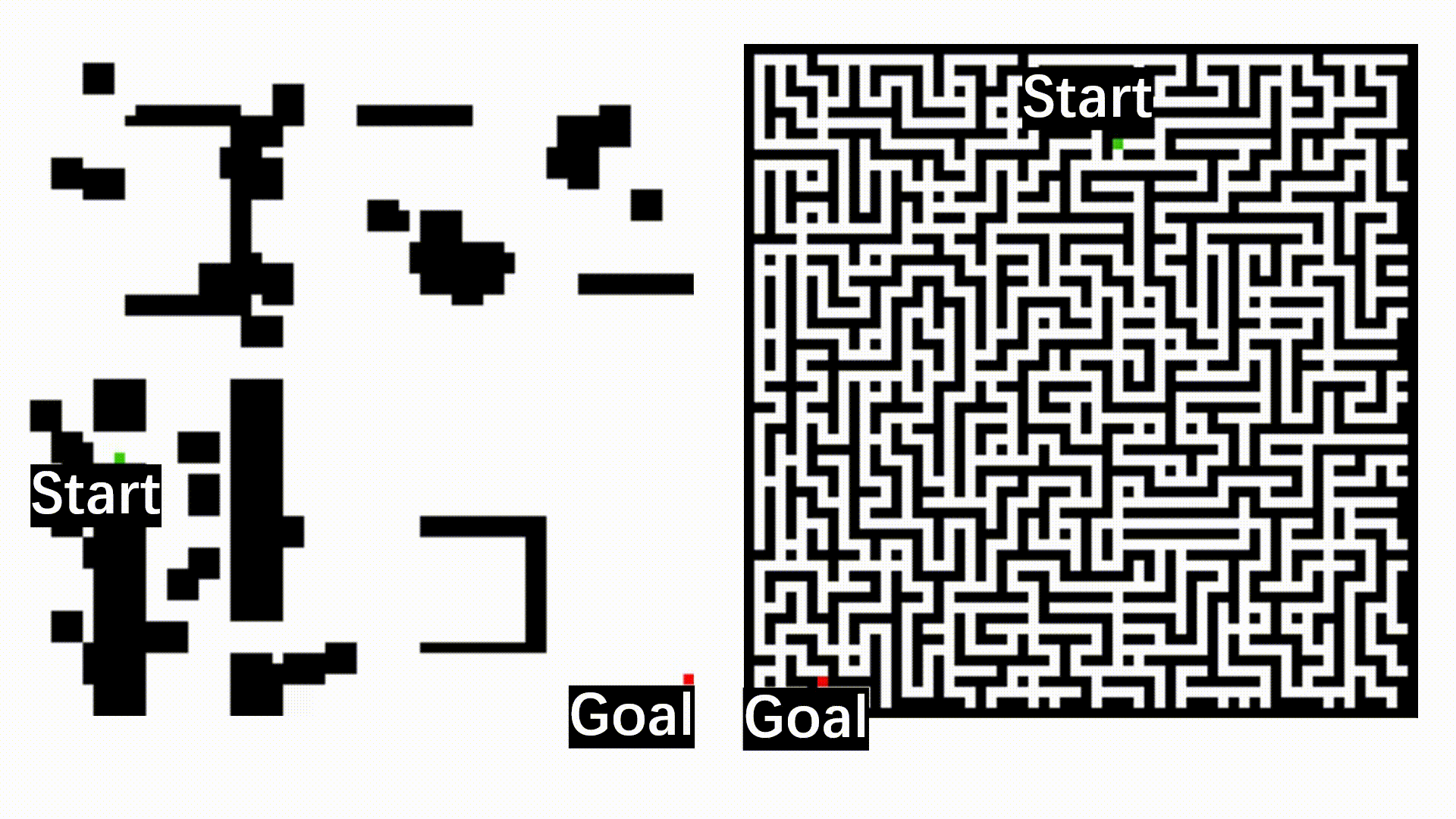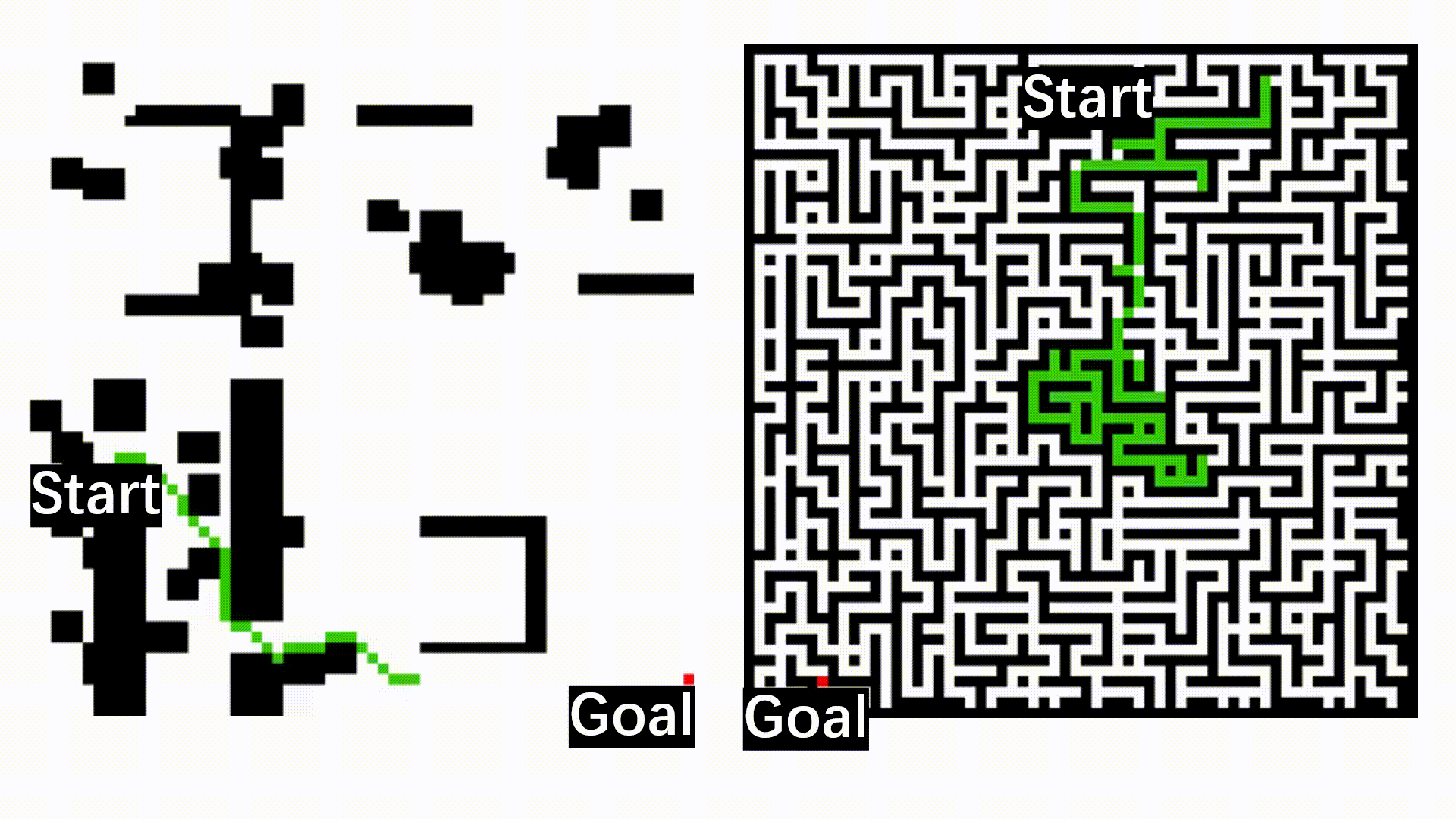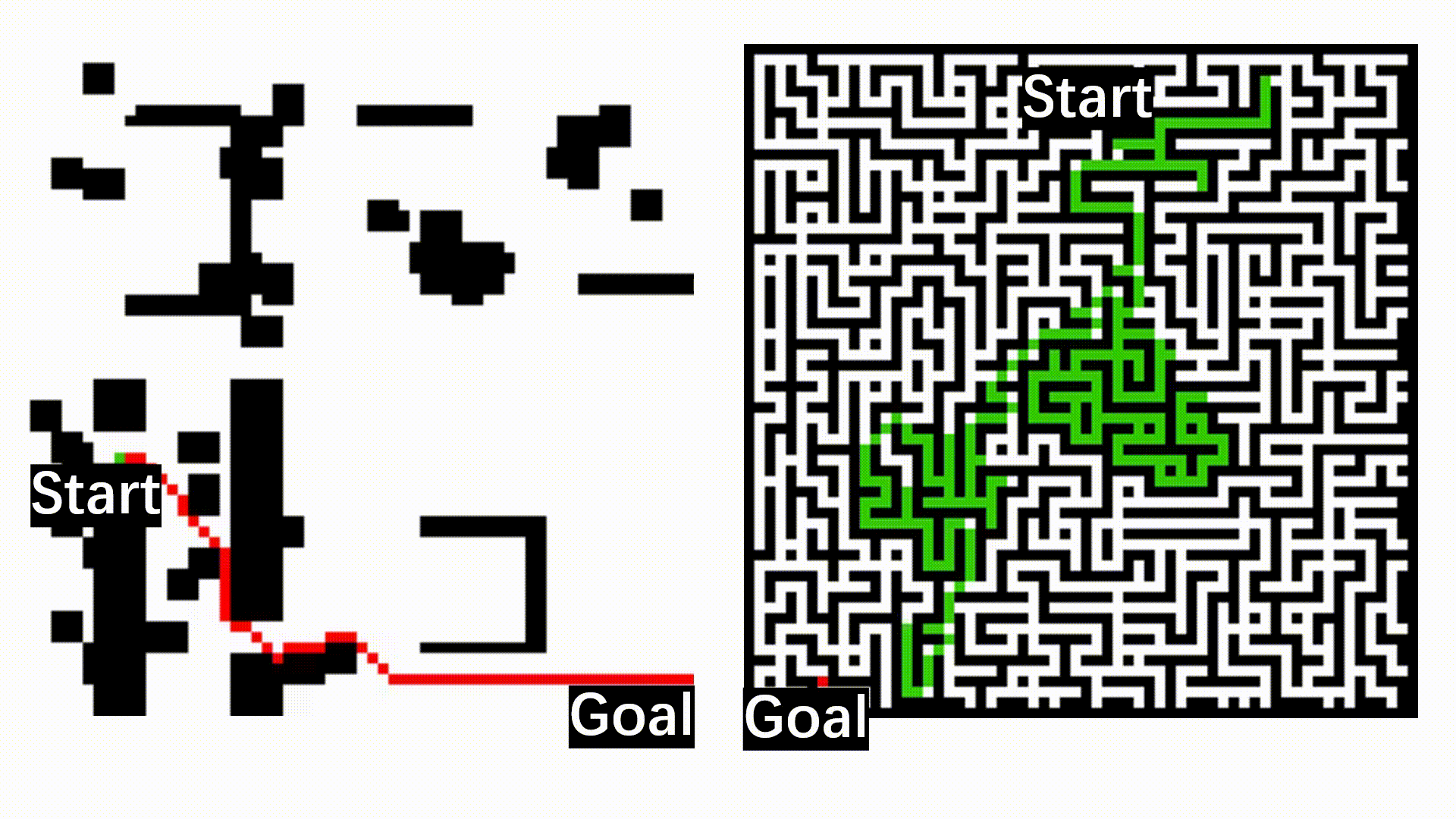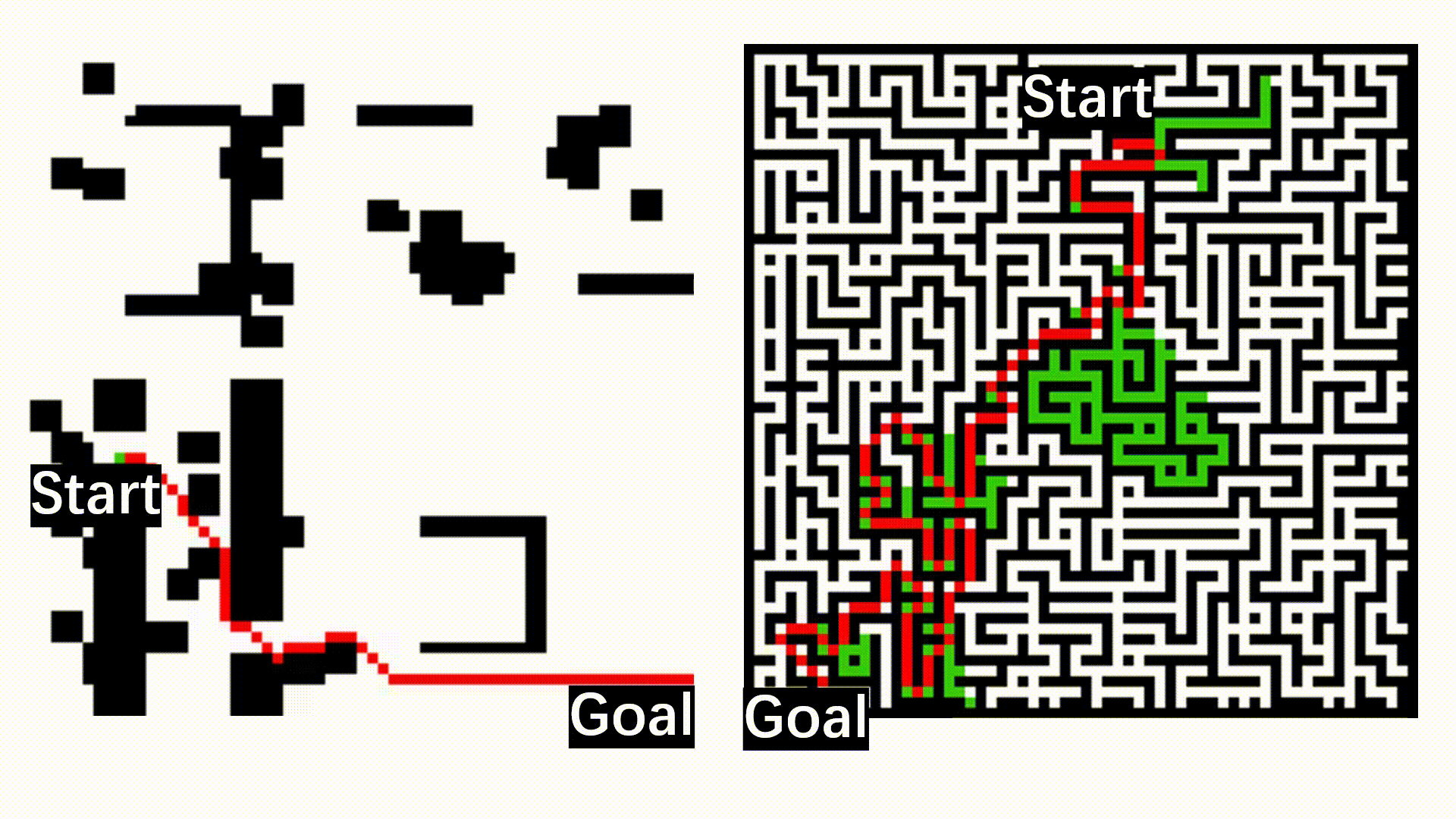 iA*: Imperative Learning-based A* Search for Path Planning.IEEE Robotics and Automation Letters (RA-L), vol. 10, no. 12, pp. 12987–12994, 2025.
iA*: Imperative Learning-based A* Search for Path Planning.IEEE Robotics and Automation Letters (RA-L), vol. 10, no. 12, pp. 12987–12994, 2025. iWalker: Imperative Visual Planning for Walking Humanoid Robot.IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 2865–2872, 2025.
iWalker: Imperative Visual Planning for Walking Humanoid Robot.IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 2865–2872, 2025. iKap: Kinematics-aware Planning with Imperative Learning.IEEE International Conference on Robotics and Automation (ICRA), pp. 10164–10170, 2025.
iKap: Kinematics-aware Planning with Imperative Learning.IEEE International Conference on Robotics and Automation (ICRA), pp. 10164–10170, 2025. iMatching: Imperative Correspondence Learning.European Conference on Computer Vision (ECCV), pp. 183–200, 2024.
iMatching: Imperative Correspondence Learning.European Conference on Computer Vision (ECCV), pp. 183–200, 2024. iPlanner: Imperative Path Planning.Robotics: Science and Systems (RSS), 2023.
iPlanner: Imperative Path Planning.Robotics: Science and Systems (RSS), 2023. Bundle Adjustment in the Eager Mode.IEEE Transactions on Robotics (T-RO), 2026.
Bundle Adjustment in the Eager Mode.IEEE Transactions on Robotics (T-RO), 2026.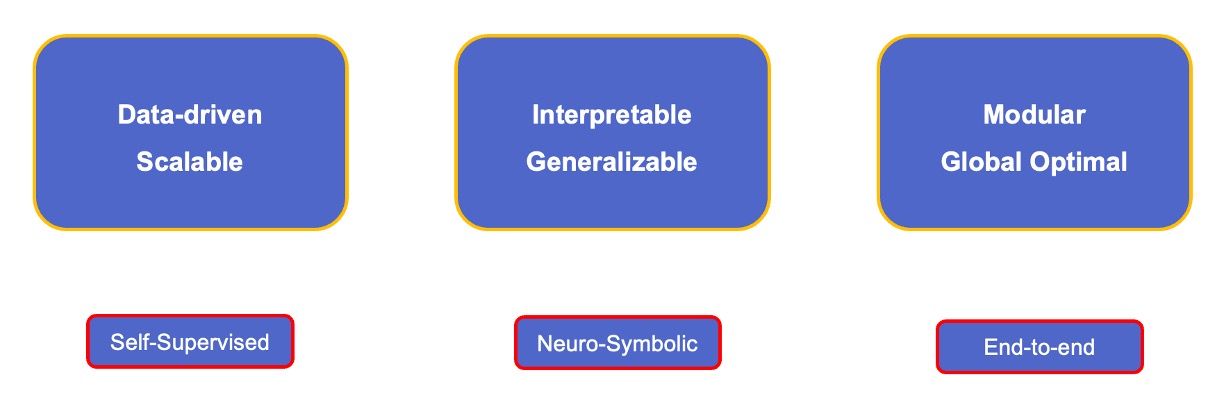
 A Self-Supervised Learning Approach with Differentiable Optimization for UAV Trajectory Planning.IEEE International Conference on Robotics and Automation (ICRA), 2026.
A Self-Supervised Learning Approach with Differentiable Optimization for UAV Trajectory Planning.IEEE International Conference on Robotics and Automation (ICRA), 2026.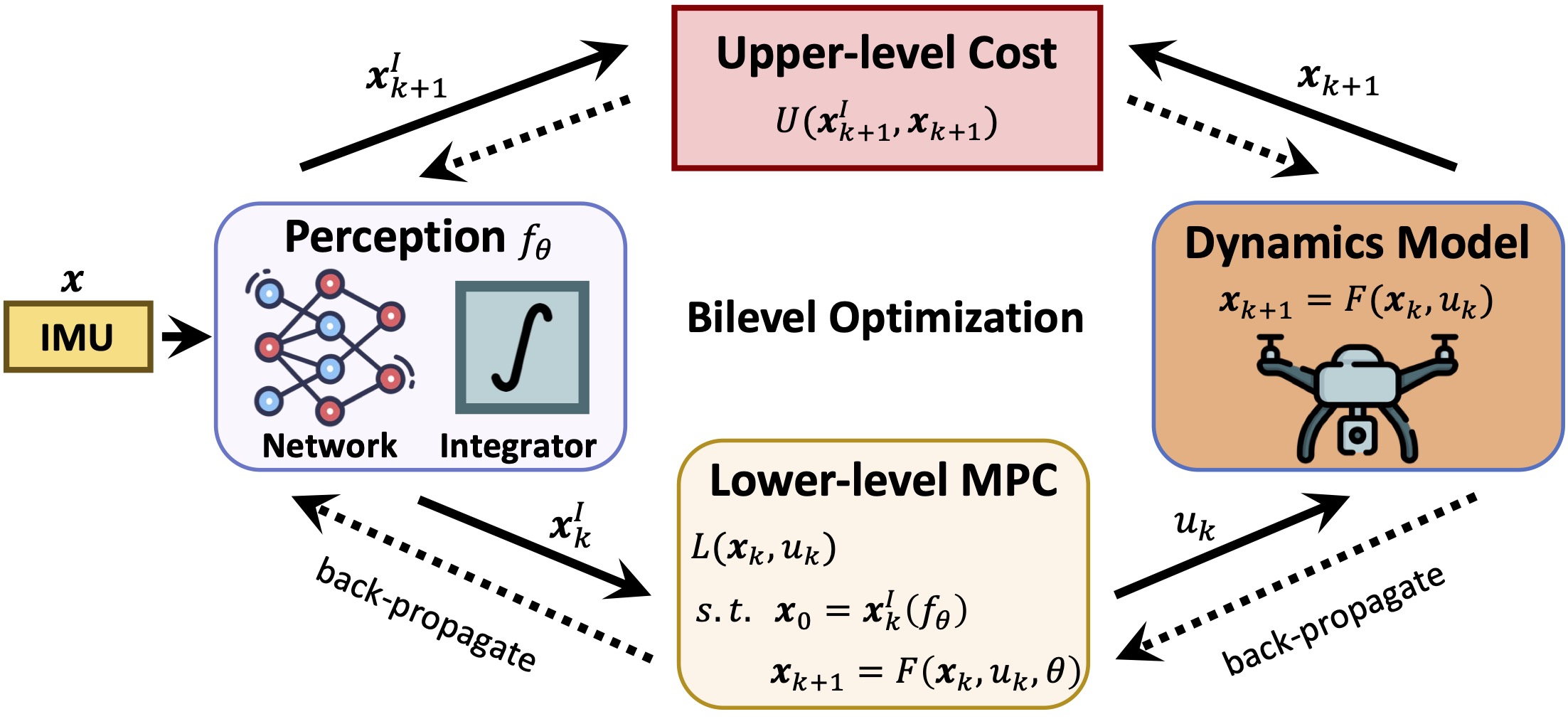 Imperative MPC: An End-to-End Self-Supervised Learning with Differentiable MPC for UAV Attitude Control.Annual Learning for Dynamics & Control Conference (L4DC), vol. 283, pp. 1140–1153, 2025.
Imperative MPC: An End-to-End Self-Supervised Learning with Differentiable MPC for UAV Attitude Control.Annual Learning for Dynamics & Control Conference (L4DC), vol. 283, pp. 1140–1153, 2025.