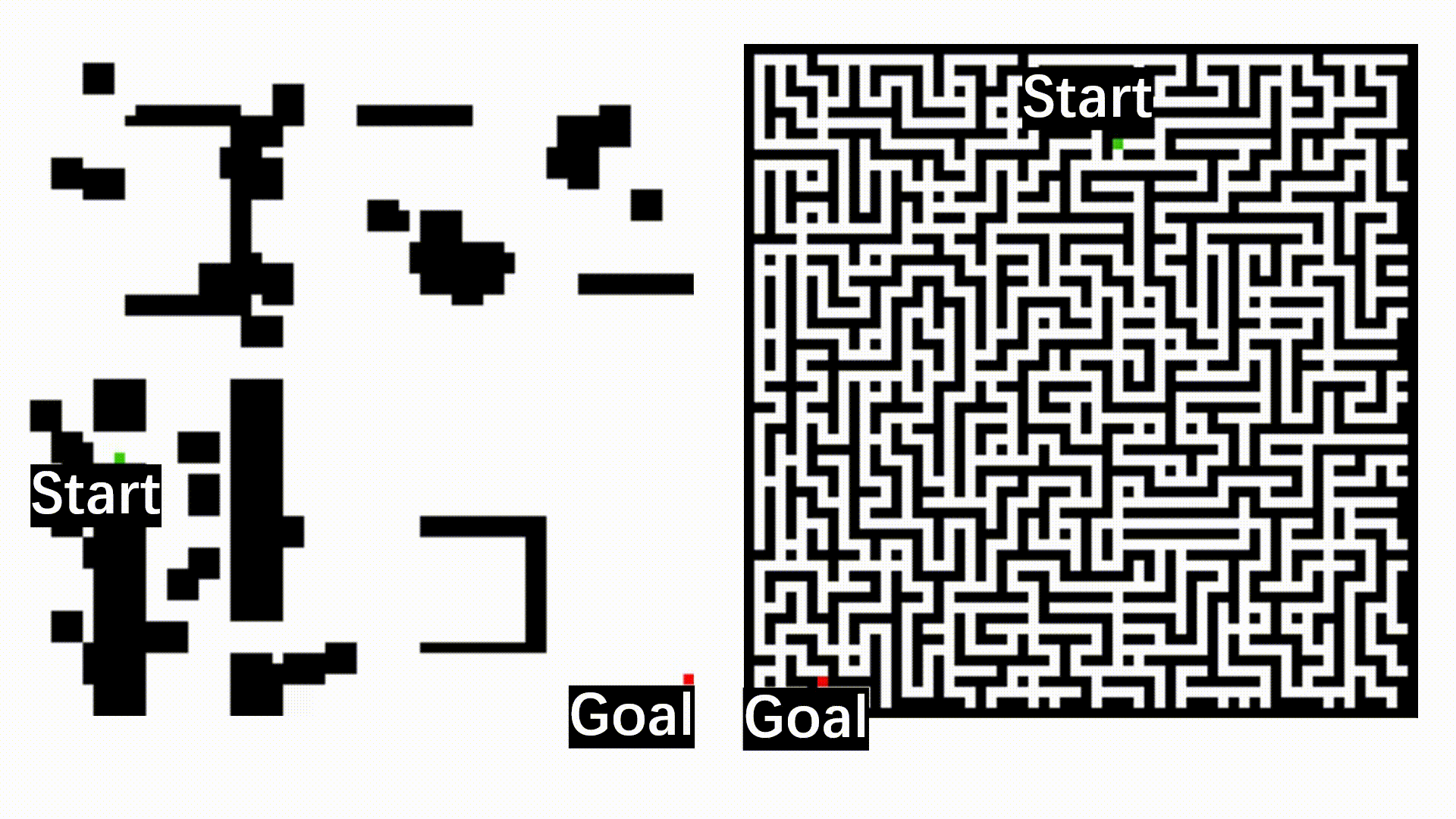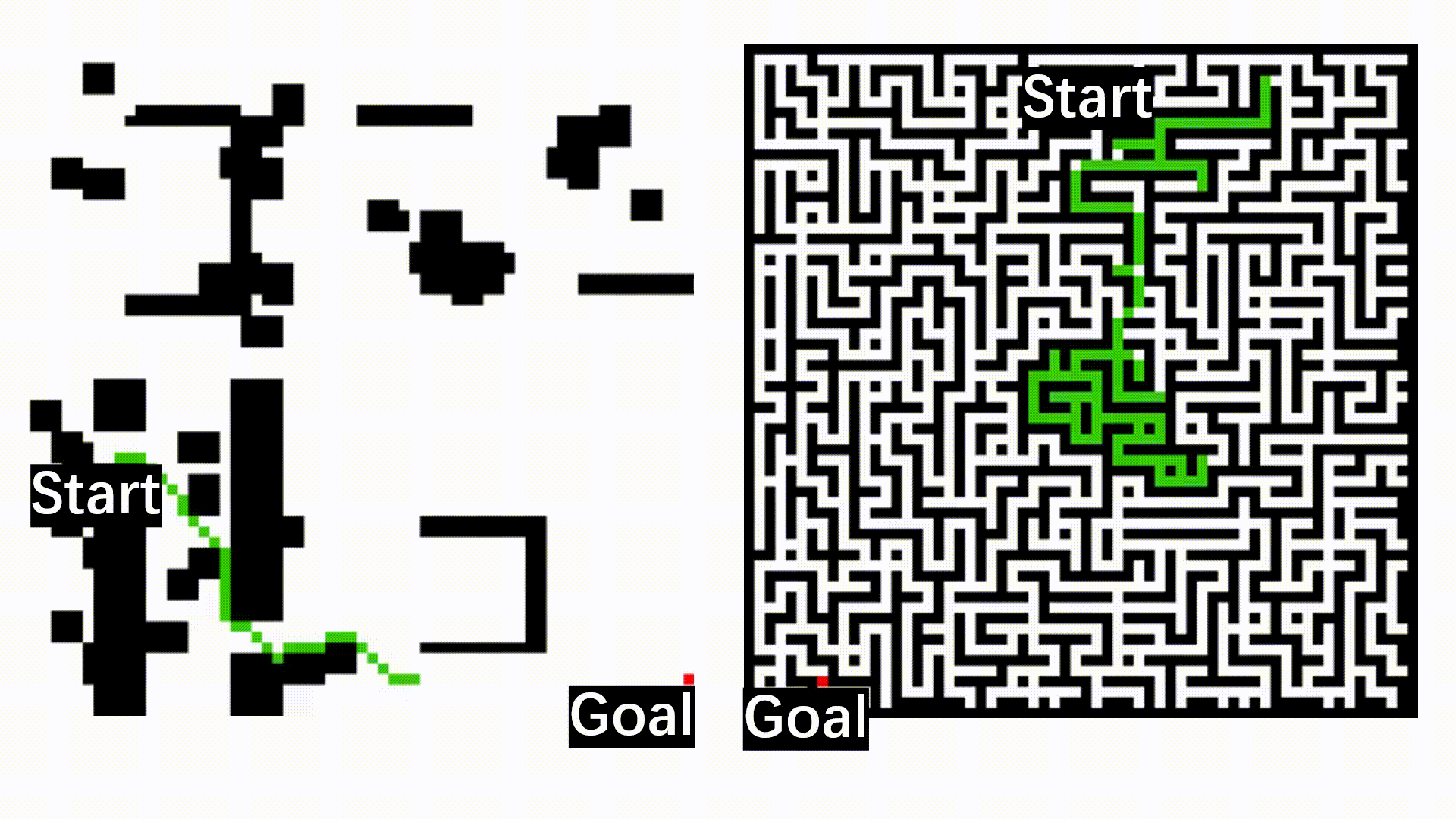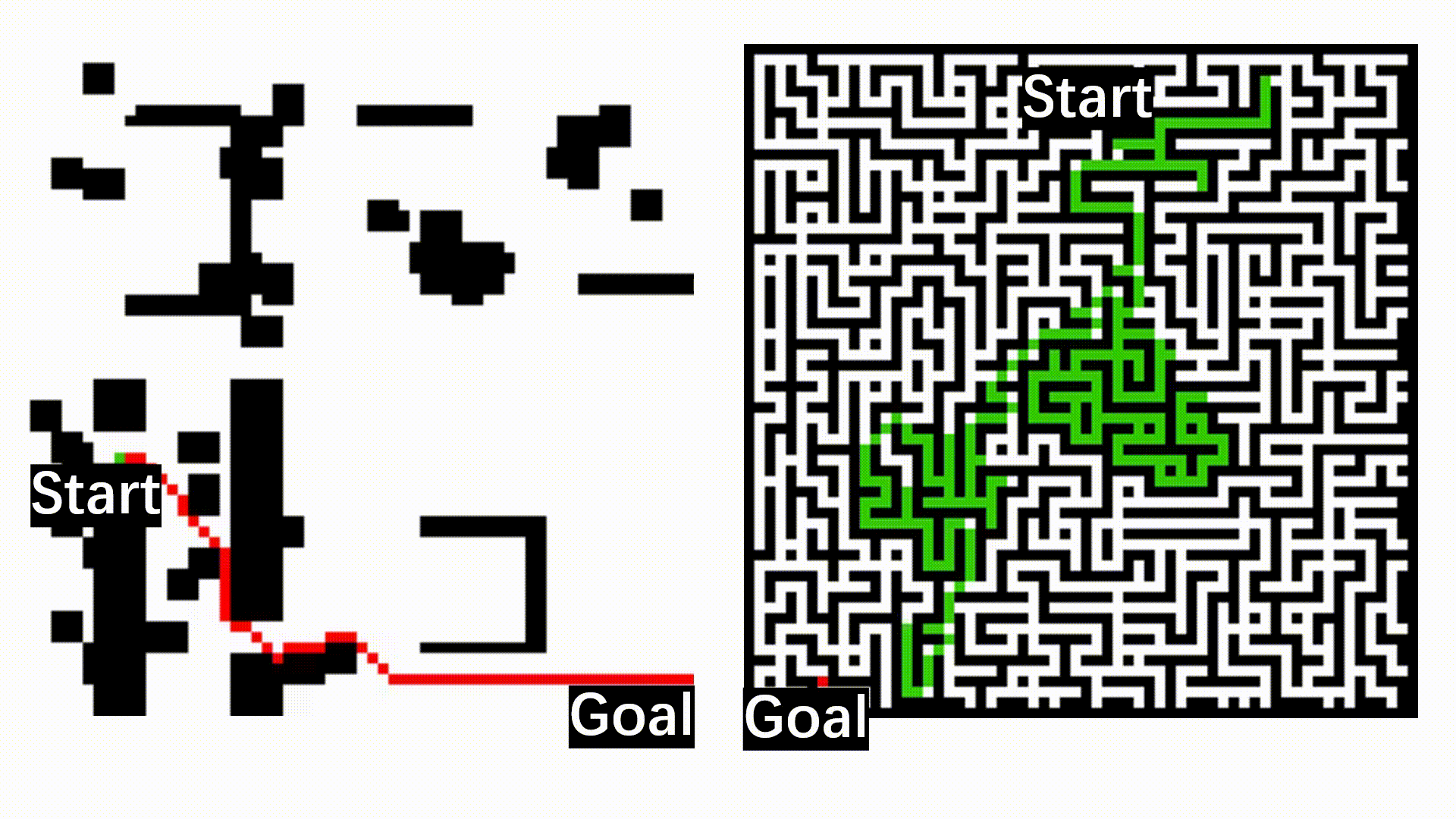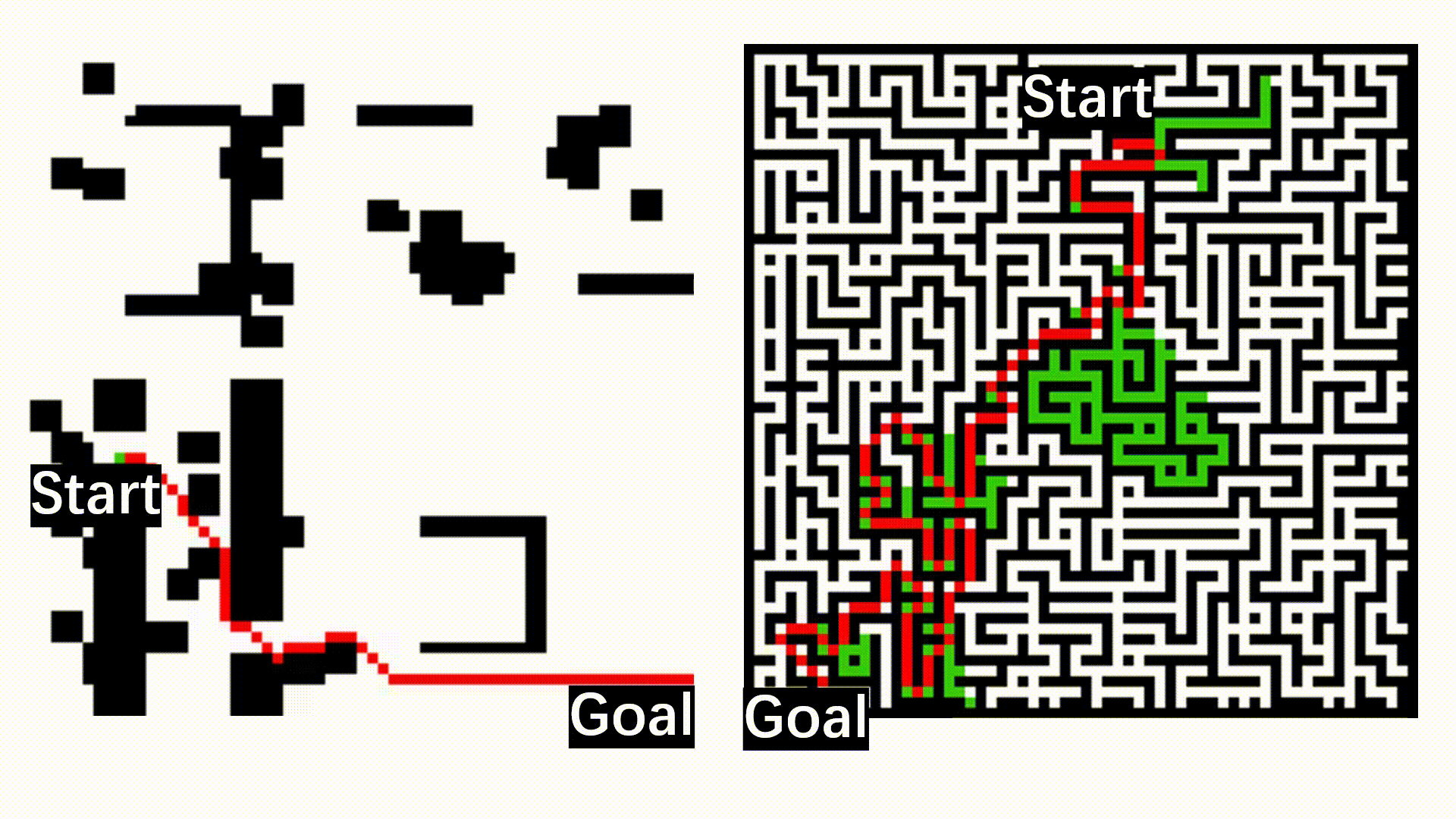
Bundle Adjustment (BA) is one of the core optimization problems in 3D vision, SLAM, and SfM. Yet modern learning systems are often split across two worlds: neural networks live in PyTorch, while BA is still handled by external C++ solvers. We introduce Bundle Adjustment in the Eager mode (BAE) to close the gap by bringing sparse, second-order BA directly into PyTorch eager mode. BAE is a PyTorch-native BA pipeline can be both flexible and fast.
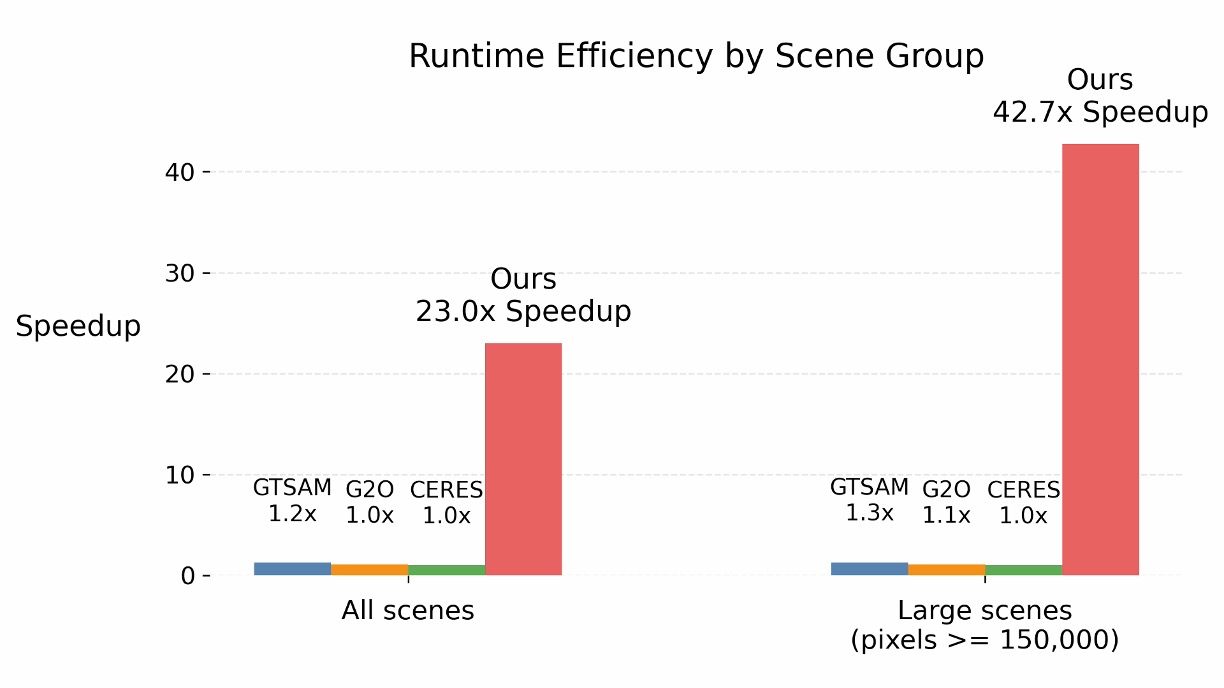
Introduction
The key idea is simple: users should be able to define BA the same way they define any other PyTorch module. Instead of switching to a separate factor-graph system or leaving Python, they can express residuals directly in the computation graph and let the optimizer infer the sparse structure needed for efficient second-order optimization.
This matters because BA is not just another differentiable layer. Its Jacobian is highly sparse: each 2D reprojection residual depends on only one camera pose and one 3D point. Traditional BA solvers exploit that sparsity aggressively. Standard dense AutoDiff does not.
PyTorch-Native Bundle Adjustment
BAE keeps the user-facing workflow close to standard PyTorch. A minimal BA example looks like this:
import torch
import pypose as pp
from torch import nn
from pypose.optim import LM
from pypose.optim.solver import PCG
from pypose.optim.strategy import TrustRegion
from pypose.optim.scheduler import StopOnPlateau
from pypose.autograd.function import psjac
class ReprojErr(nn.Module):
def __init__(self, poses, points):
super().__init__()
self.poses = pp.Parameter(poses, sjac=True)
self.points = pp.Parameter(points, sjac=True)
@psjac
def project(poses, points):
points = poses.Act(points)
return -points[..., :2] / points[..., [2]]
def forward(self, pixels, cidx, pidx):
poses = self.poses[cidx]
points = self.points[pidx]
return ReprojErr.project(poses, points) - pixels
torch.set_default_device("cuda")
num_points, poses = 8, pp.randn_SE3(1)
points = torch.randn(num_points, 3)
points[:, 2] += 4
camera_index = torch.zeros(num_points, dtype=torch.long)
point_index = torch.arange(num_points)
pixels = torch.randn(num_points, 2)
inputs = (pixels, camera_index, point_index)
model = ReprojErr(poses, points)
solver = PCG(tol=1e-4, maxiter=250)
strategy = TrustRegion(up=2.0, down=0.5**4)
optimizer = LM(model, solver, strategy, sparse=True)
scheduler = StopOnPlateau(optimizer, steps=5, verbose=True)
while scheduler.continual():
loss = optimizer.step(inputs)
scheduler.step(loss)
The optimization target is the usual one for BA: given camera poses, 3D points, and 2D observations, update the variables so that projected points align with measured pixels. The extra ingredients are minimal:
sjac=Truemarks parameters whose Jacobians should be traced as sparse rather than dense.@psjacmarks functions whose sparse Jacobian assembly should be parallelized.
Once the model is defined, the optimizer still looks like a standard PyPose or PyTorch setup, with a configurable linear solver and trust-region strategy.
Why Sparse Jacobians Matter
The main obstacle is not whether PyTorch can differentiate BA. It can. The real challenge is whether PyTorch can differentiate BA with the right sparsity structure.
In large-scale BA, dense Jacobians are prohibitively expensive. In the Ladybug scene from the BAL dataset, a dense Jacobian in double precision would require about 5.2 TB of memory, while the corresponding sparse Jacobian needs only about 125 MB. That gap is the difference between an impractical prototype and a usable system.
To address this, the framework introduces a sparsity-aware autodiff mechanism that dynamically traces tensor operations and infers the Jacobian block structure directly from the computation graph. This allows PyTorch to compute only the derivatives that actually exist in the BA problem.
Sparse Second-Order Optimization in PyTorch
The sparse Jacobian is stored using native PyTorch sparse tensors, especially the sparse_bsr format, which is well suited to block-sparse matrices. This design avoids introducing a custom factor-graph data structure and keeps the programming model close to ordinary tensor code.
BA is then solved with sparse Levenberg-Marquardt, which repeatedly forms and solves the normal equations
\[(J^T J + \lambda \, \mathrm{diag}(J^T J)) \Delta \theta = -J^T R.\]That workflow depends on sparse matrix-matrix products, matrix-vector products, diagonal operations, and sparse linear solvers. Since PyTorch does not fully support all of the required sparse BSR operators, the system implements GPU sparse operators and registers them through the PyTorch dispatcher. As a result, users can still write expressions such as A = J.T @ J rather than relying on a separate, specialized solver API.
This combination of sparse-aware AutoDiff and GPU sparse linear algebra gives the framework three practical benefits:
- The flexibility of PyTorch eager execution
- The efficiency expected from traditional BA solvers
- Large-scale GPU acceleration for nonlinear optimization
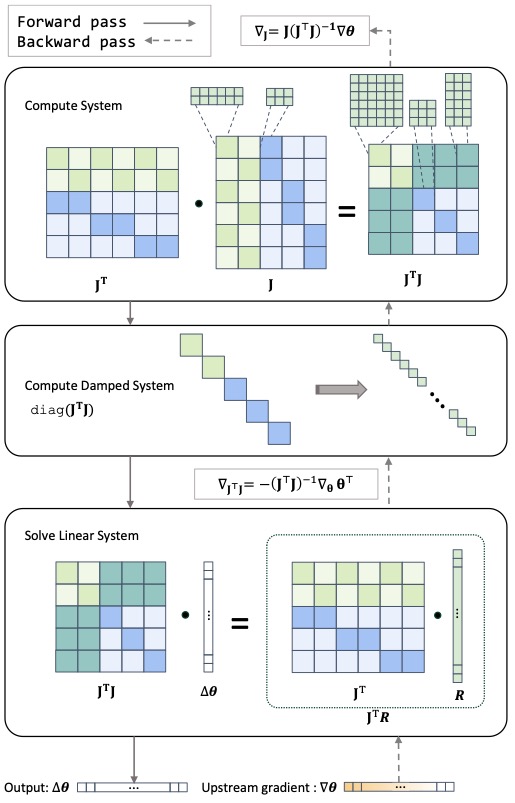
Beyond Bundle Adjustment
Although the paper focuses on BA, the framework is more general than a single benchmark or a hand-written kernel. The same mechanism can also support other sparse optimization problems such as Pose Graph Optimization (PGO), where indexing patterns and Lie-group operations define similarly structured Jacobian blocks.
In that sense, this work is not only a BA implementation. It is a broader sparse second-order optimization infrastructure for PyTorch, making it easier to combine geometry, learning, and optimization inside one differentiable pipeline.
Resources
- Full Example: PyPose BA example
- Documentation: PyPose psjac API
Publication
-
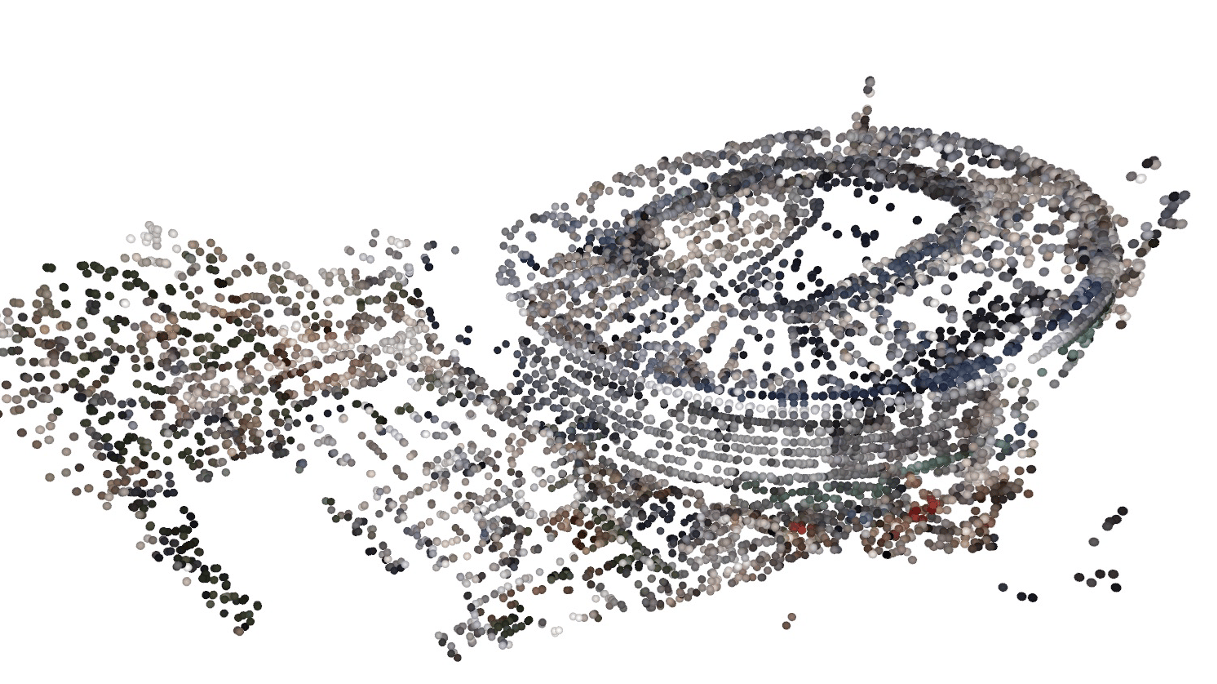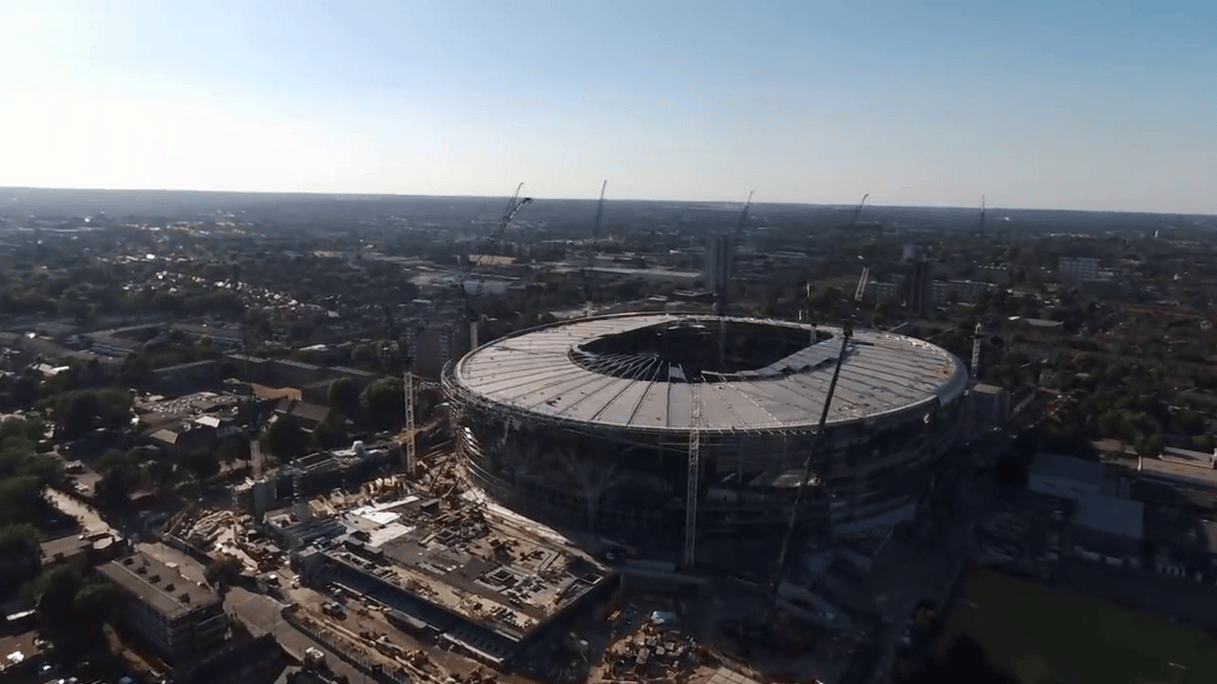 Bundle Adjustment in the Eager Mode.IEEE Transactions on Robotics (T-RO), 2026.
Bundle Adjustment in the Eager Mode.IEEE Transactions on Robotics (T-RO), 2026.