Introduction
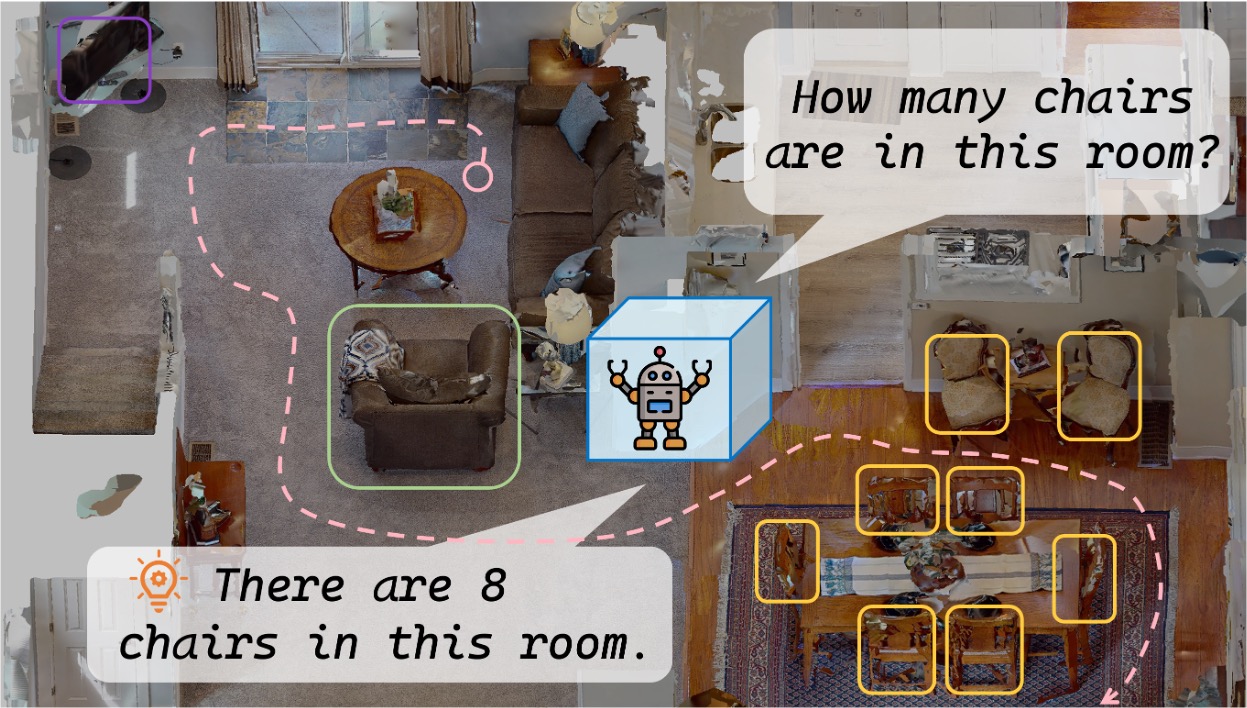
Reasoning-based vision-language navigation requires autonomous robots to bridge massive logical gaps to understand abstract human instructions, such as inferring that a weather report indicating rain requires finding a waterproof jacket. Furthermore, the robot must conduct efficient exploration across large-scale, unknown environments to locate those specific targets without aimless wandering. To address the limitations of existing methods, we propose VL-Nav, a neuro-symbolic system that fundamentally intertwines neural semantic understanding with symbolic guidance for rapid, task-guided exploration. Validated on the navigation tasks of DARPA TIAMAT Challenge Phase 1, VL-Nav achieved an 83.4% success rate in indoor settings and 75% in unstructured outdoor environments. Moreover, our real-world deployments achieved an 86.3% success rate across challenging scenarios, including a 483-meter long-range trajectory and a complex 3D multi-floor demonstration.
Neuro-Symbolic (NeSy) Exploration System Overview
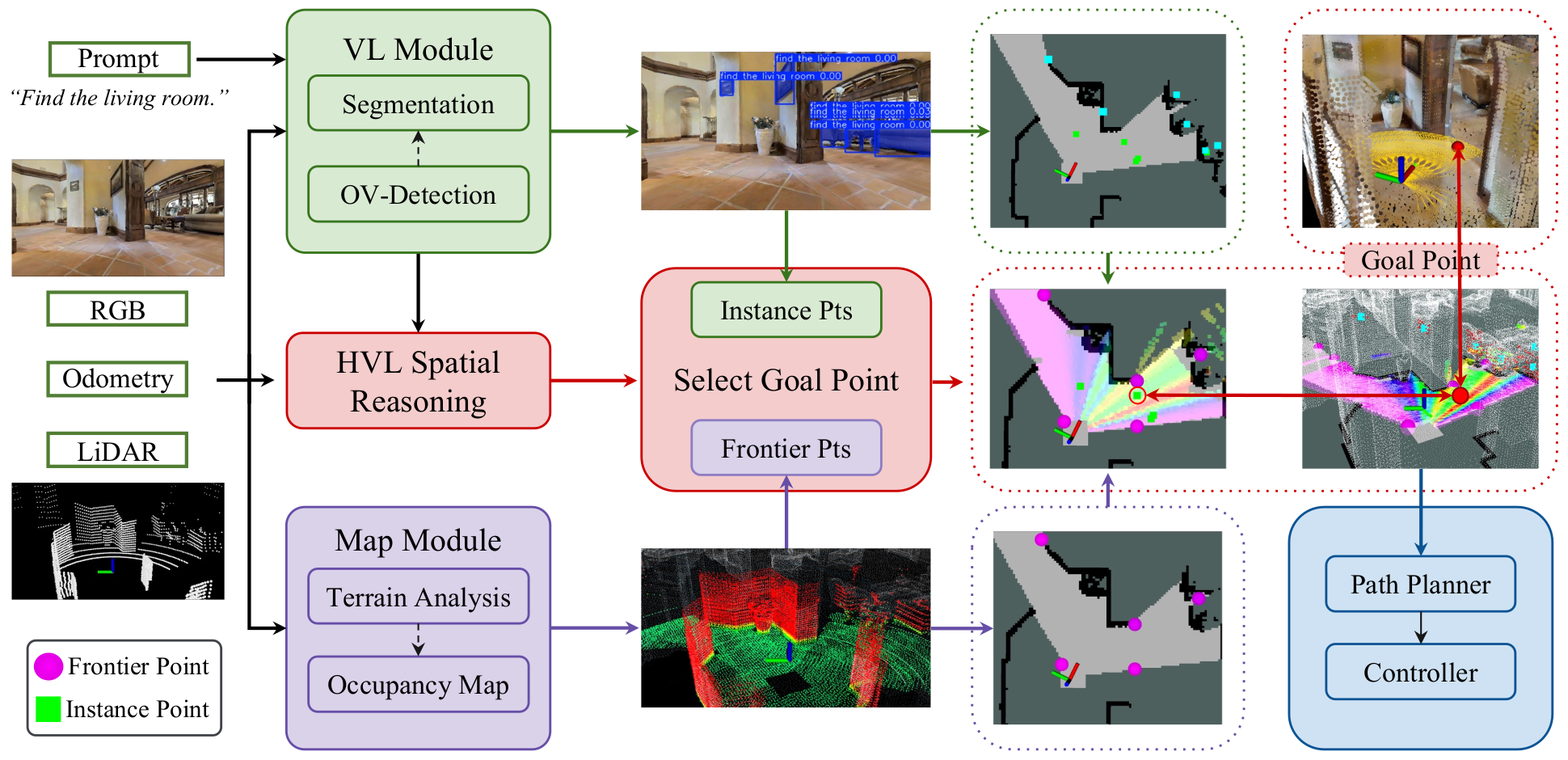
An overview of the Neuro-Symbolic (NeSy) exploration system. It processes inputs including prompts, RGB images, poses, and LiDAR scans. The Vision-Language (VL) module conducts open-vocabulary detection to identify objects related to the prompt, generating instance-based target points. Concurrently, the map module performs terrain analysis and manages a dynamic occupancy map. Frontier-based target points are then identified based on this occupancy map, along with the instance points, forming a candidate points pool. Finally, this system employs the NeSy scoring to select the most effective goal point.
Experiments & Demonstrations
We comprehensively evaluated VL-Nav in both high-fidelity simulations and physical deployments to test its reasoning and multi-target exploration capabilities.
Simulation (DARPA TIAMAT Challenge Phase 1)
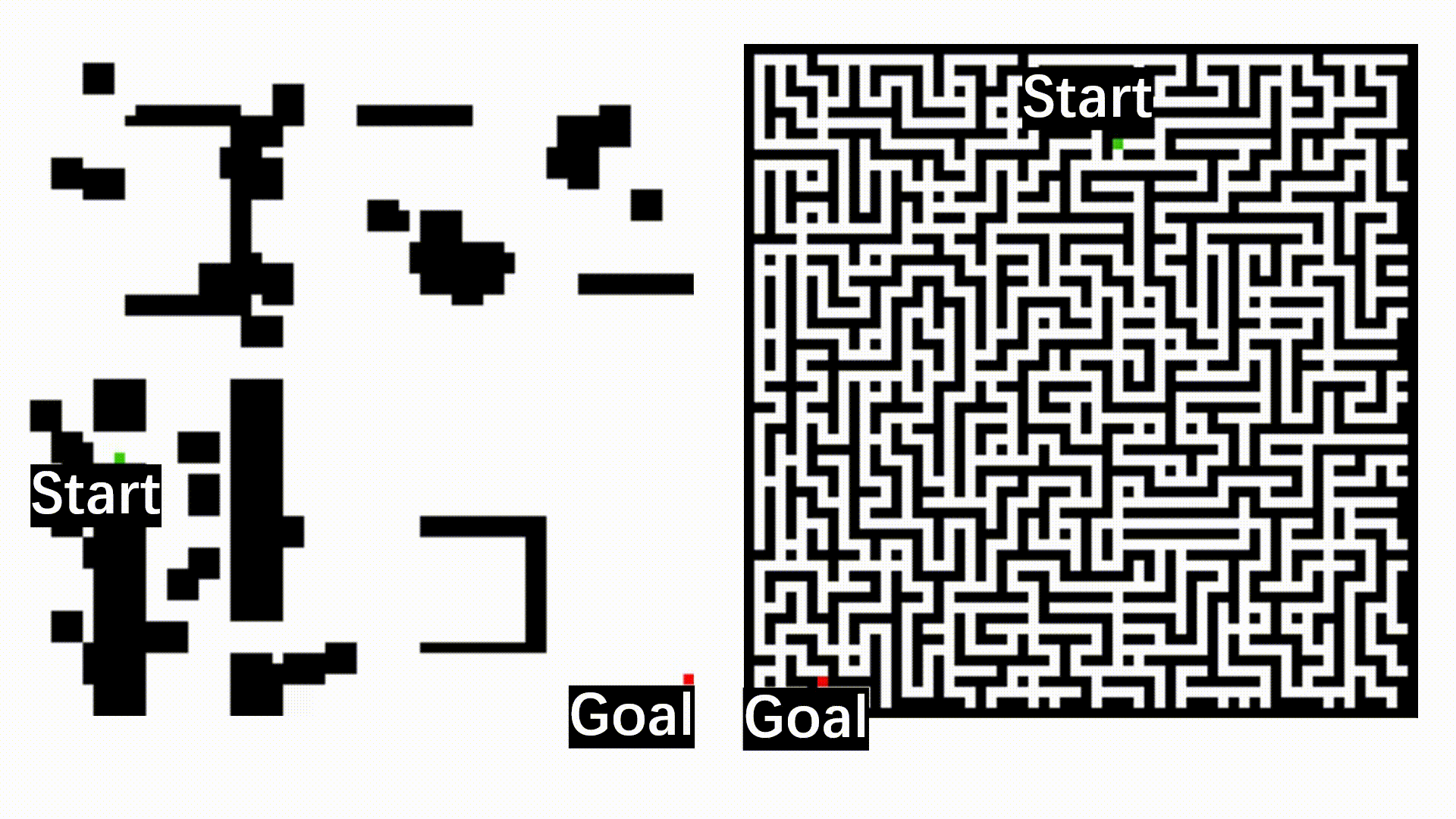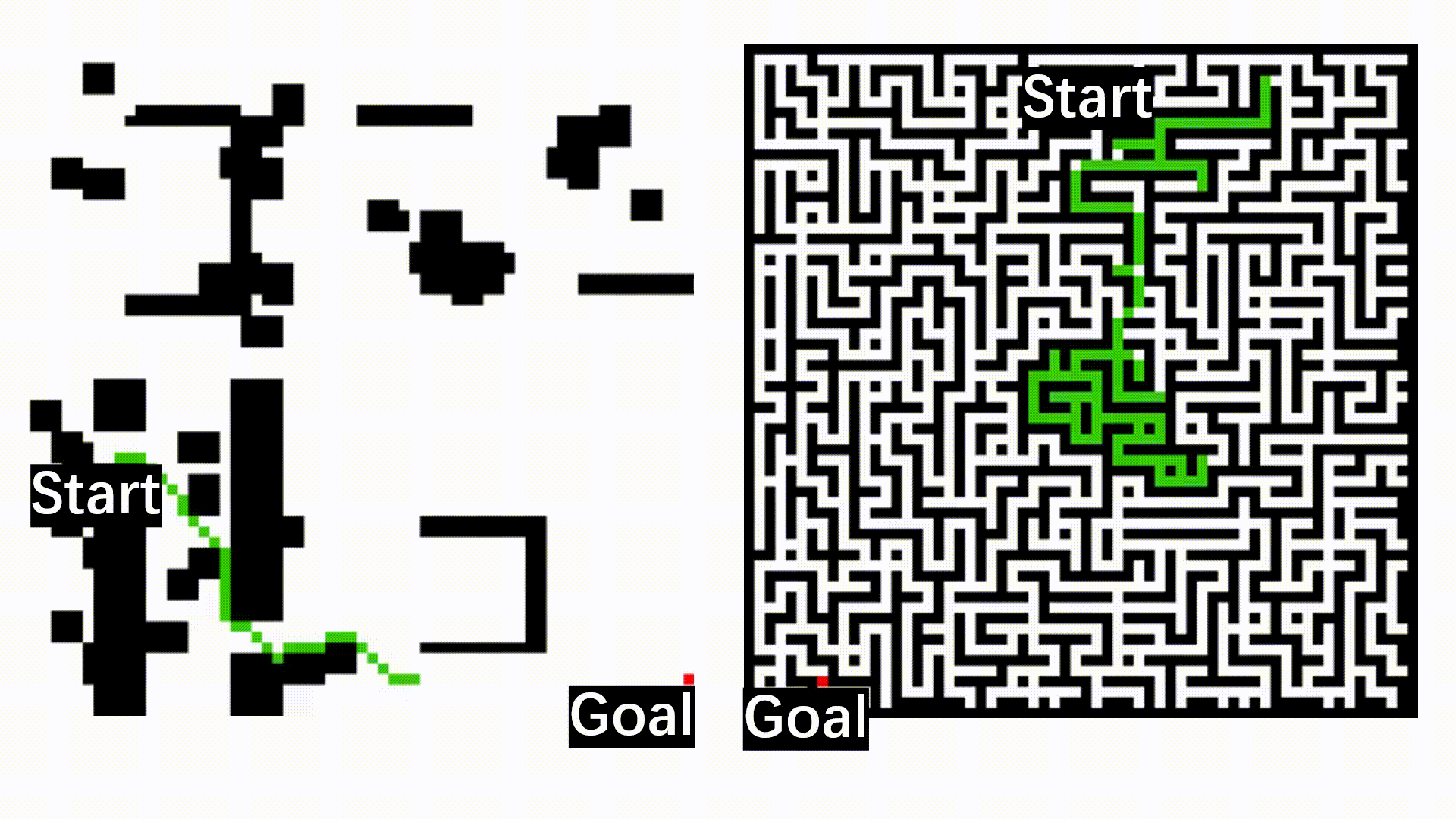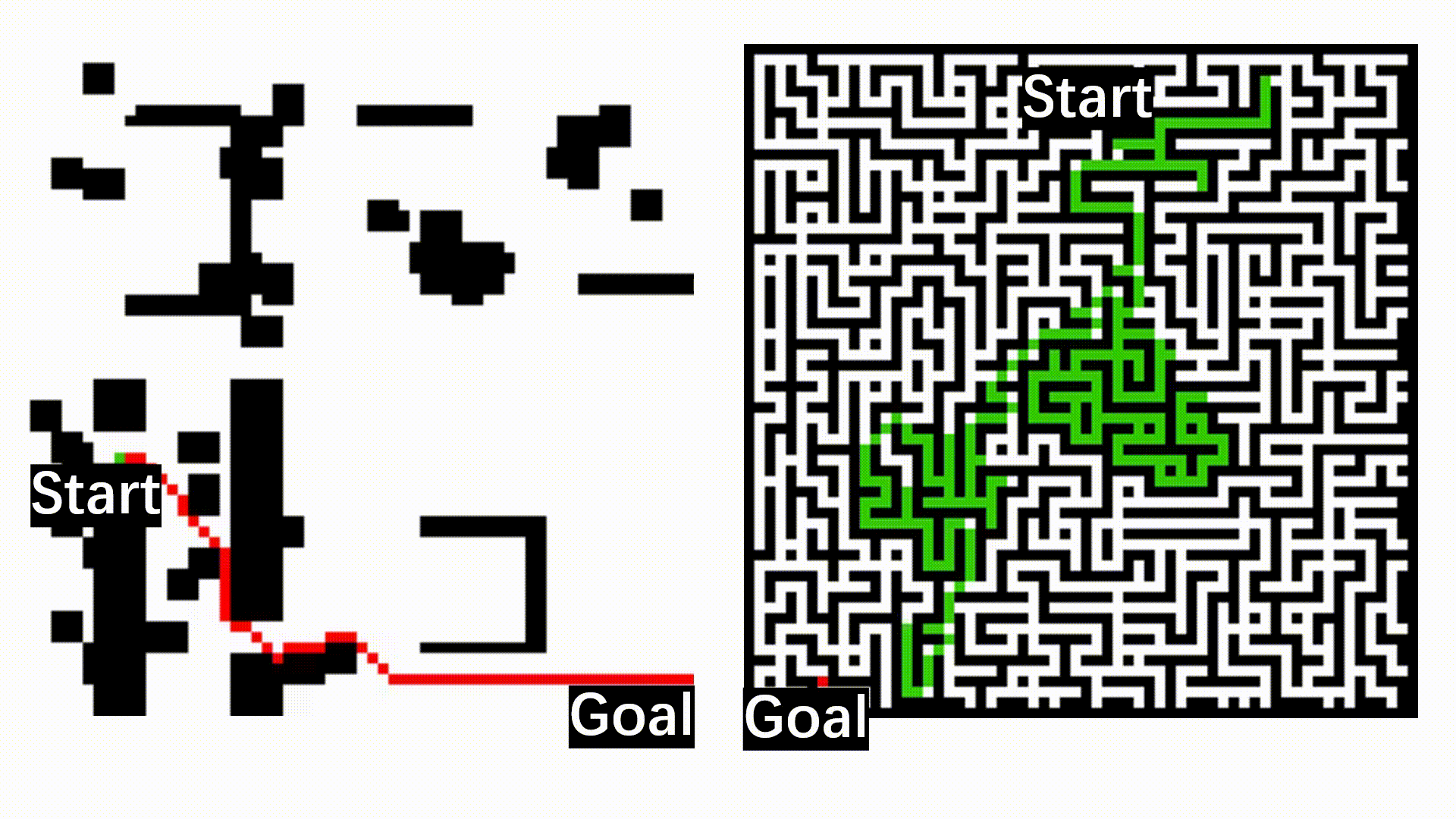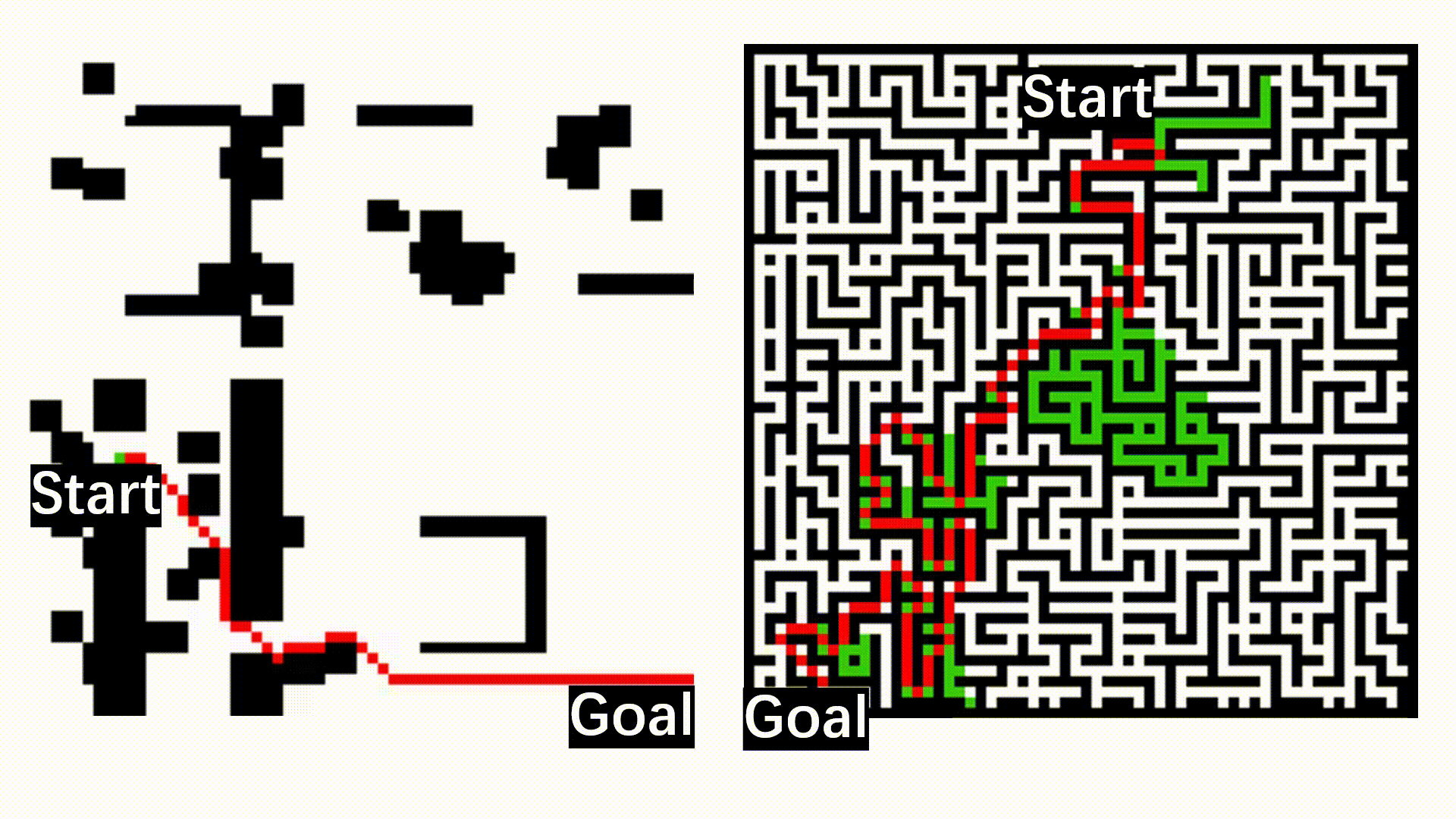
VL-Nav was evaluated in complex indoor (HabitatSim) and unstructured outdoor (IsaacSim) environments. Our system successfully resolved abstract logic and long-horizon tasks, achieving success rates ranging from 75.0% to 87.5% across all scenarios. It significantly outperformed foundation model baselines, which frequently timed out or struggled with aimless wandering.
Real-World Deployments
We deployed the real-time navigation stack on our wheeled robot (Rover) with an edge device (Jetson Orin NX) across four physical environments varying in scale and semantic complexity: a Hallway, an Office, an Apartment, and an Outdoor area.
- Performance: VL-Nav achieved an overall 86.3% success rate, delivering vastly superior path efficiency (SPL) compared to classical frontier exploration and VLFM baselines, including successfully executing a 483-meter long-range trajectory.
- Demonstrations: Additionally, we demonstrated our system on a Unitree G1 humanoid robot (Gideon) in the office, and on a Unitree Go2 quadruped robot (Nova) in the teaching building to showcase the complex 3D multi-floor navigation task. The robots successfully transitioned between floors, grounded spatial relations, and visually verified targets.
Demo Videos of the Indoor Habitat environment - DARPA TIAMAT Challenge Phase 1:
Demo Videos of Outdoor IsaacSim environments - DARPA TIAMAT Challenge Phase 1:
Demo Videos of Real Robot Experiments
Demo Video of Humanoid Robot:
Demo Video of Multi-Floor and Multi-Step Navigation Task:
Acknowledgements
We would like to credit and thank the following backbones used in this work:
- Resilient State Estimation: Super Odometry
- Open-Vocabulary Detection & Segmentation: YOLO-World and FastSAM
- Vision-Language Reasoning: Qwen3-VL