Autonomous exploration has many important applications. However, classic information gain-based or frontier-based exploration only relies on the robot current state to determine the immediate exploration goal, which lacks the capability of predicting the value of future states and thus leads to inefficient exploration decisions. We present a method to learn how “good” states are, measured by the state value function, to provide a guidance for robot exploration in real-world challenging environments. Our work is formulated as a Off-Policy Evaluation for Robot Exploration (OPERE). It consists of offline Monte-Carlo training on real-world data and performs Temporal Difference (TD) online adaptation to optimize the trained value estimator. We also design an intrinsic reward function based on sensor information coverage to enable the robot to gain more information with sparse extrinsic rewards. Results demonstrate that OPERE enables the robot to predict the value of future states so as to better guide robot exploration. The proposed algorithm achieves better prediction performance compared with other state-of- the-art OPE methods. To the best of our knowledge, OPERE for the first time demonstrates value function prediction on real- world dataset for robot exploration in challenging subterranean and urban environments.
Method Overview
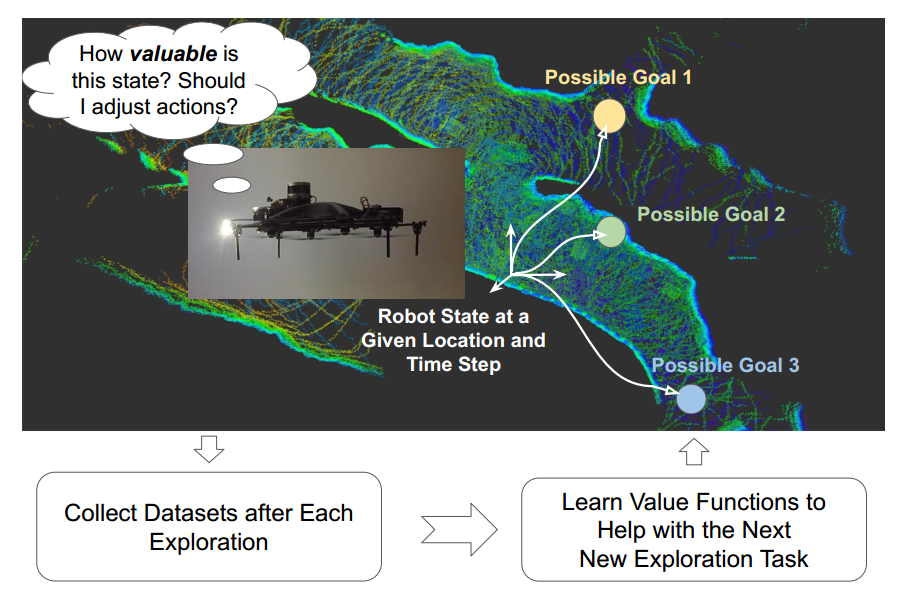
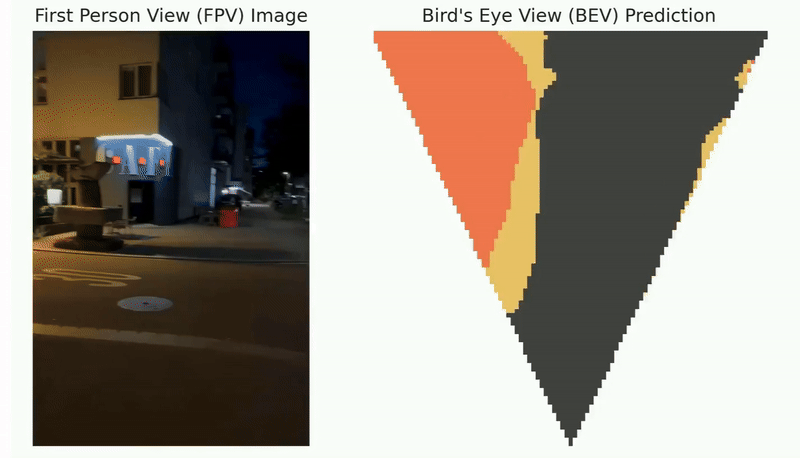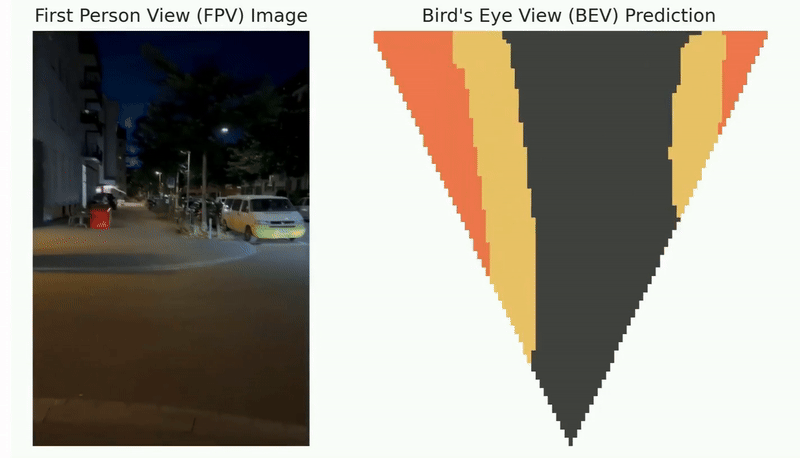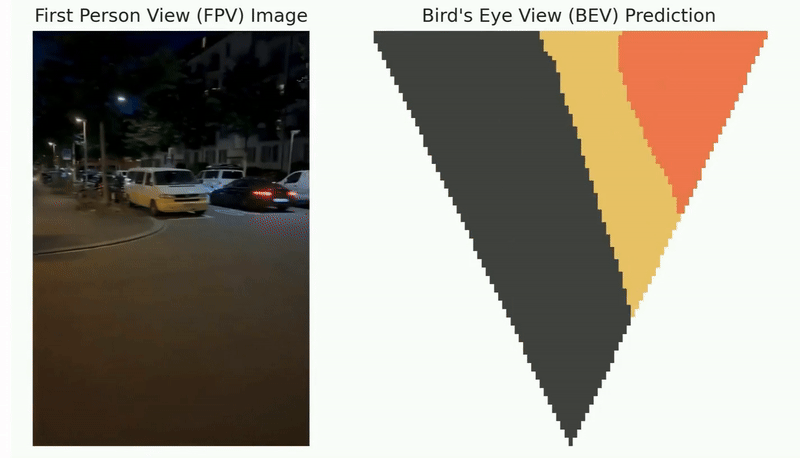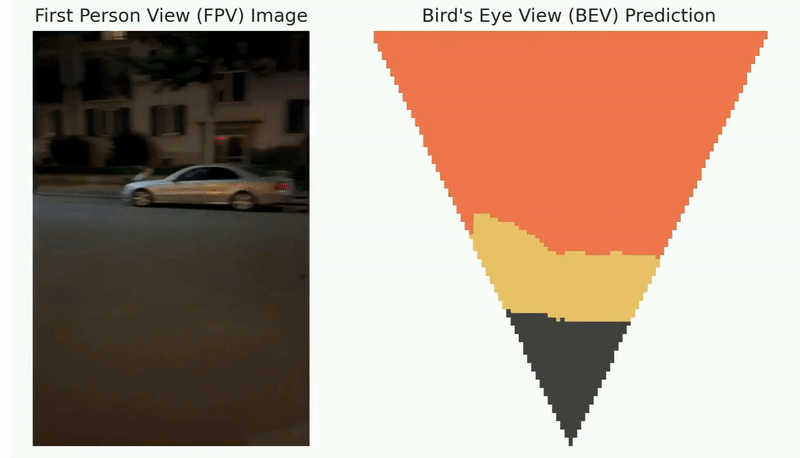
Our method consisits of offline learning and online adaptation. First we collect datasets which consist of camera images and projected map images. Then we feed the data to the value function network and perform offline MC learning, where the camera image and map projection image are sent to the encoders in parallel and then aggregated together to obtain the state value function. During the online deployment, we perform one additional TD adaptation step and get the refined value function.
Dataset Collection
Different from the traditional line processing pipelines in visual odometry systems, we propose an illumination-robust line tracking method, where point feature tracking and distribution of point and line features are utilized to match lines. By accelerating the feature extraction and matching network using Nvidia TensorRT Toolkit, AirVO can run in real time on GPU.

Experimental Results
With the learned value function, robot could make better decisions.
Regret Analysis in Corridor Environment (left) and Cave Environment (right)
Real Robot Experiments
Robot Explores with Learned Value Function
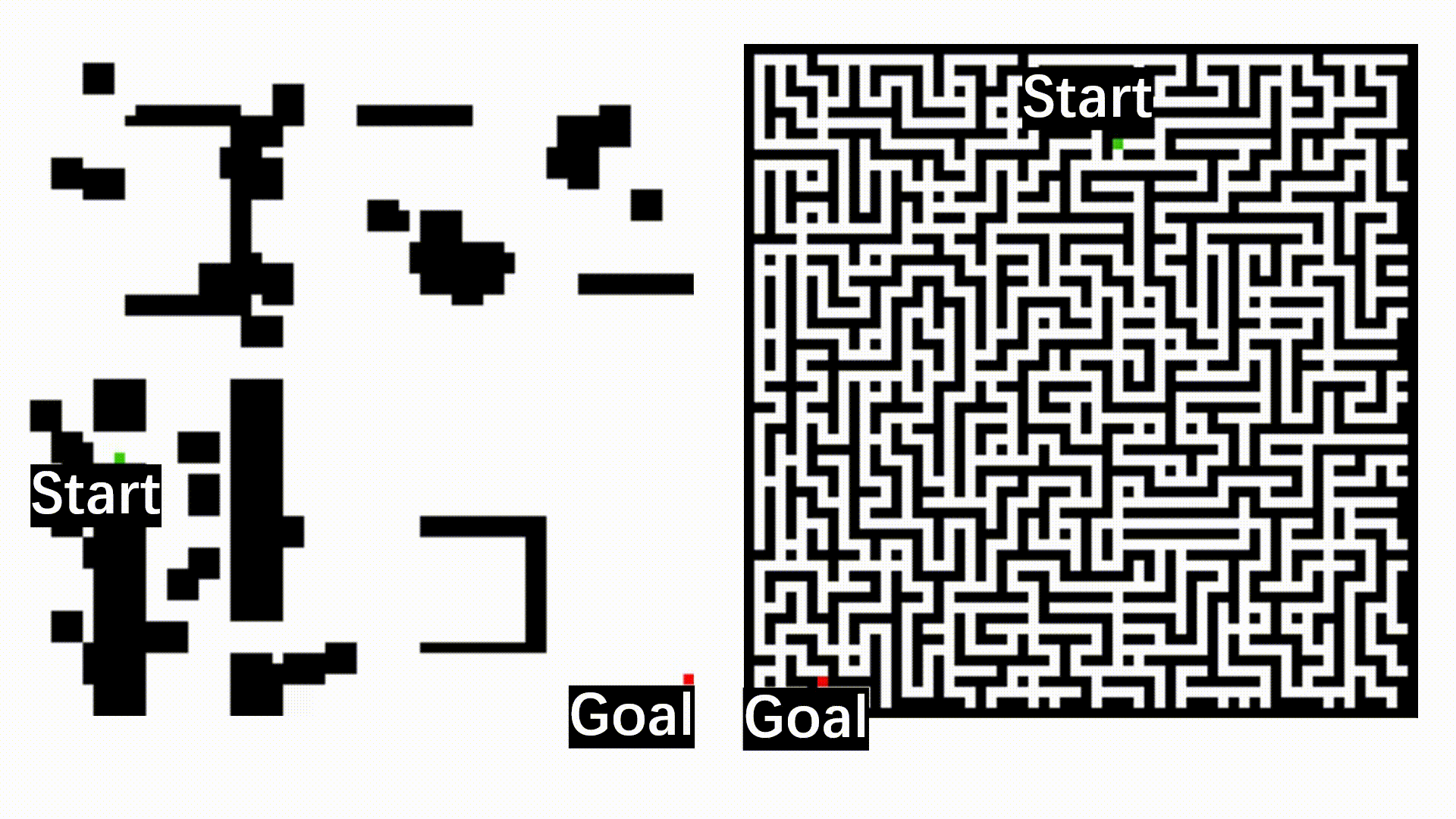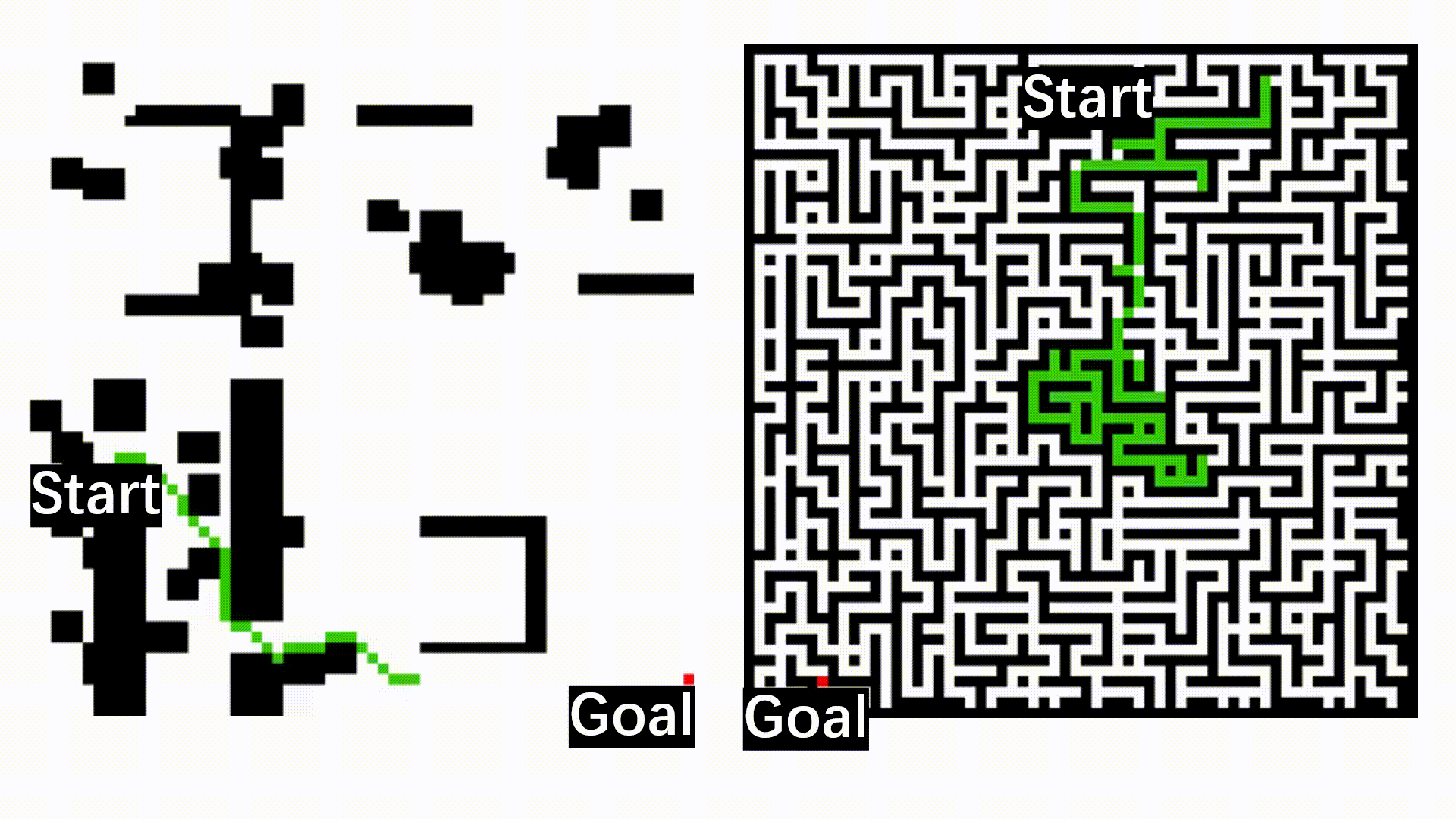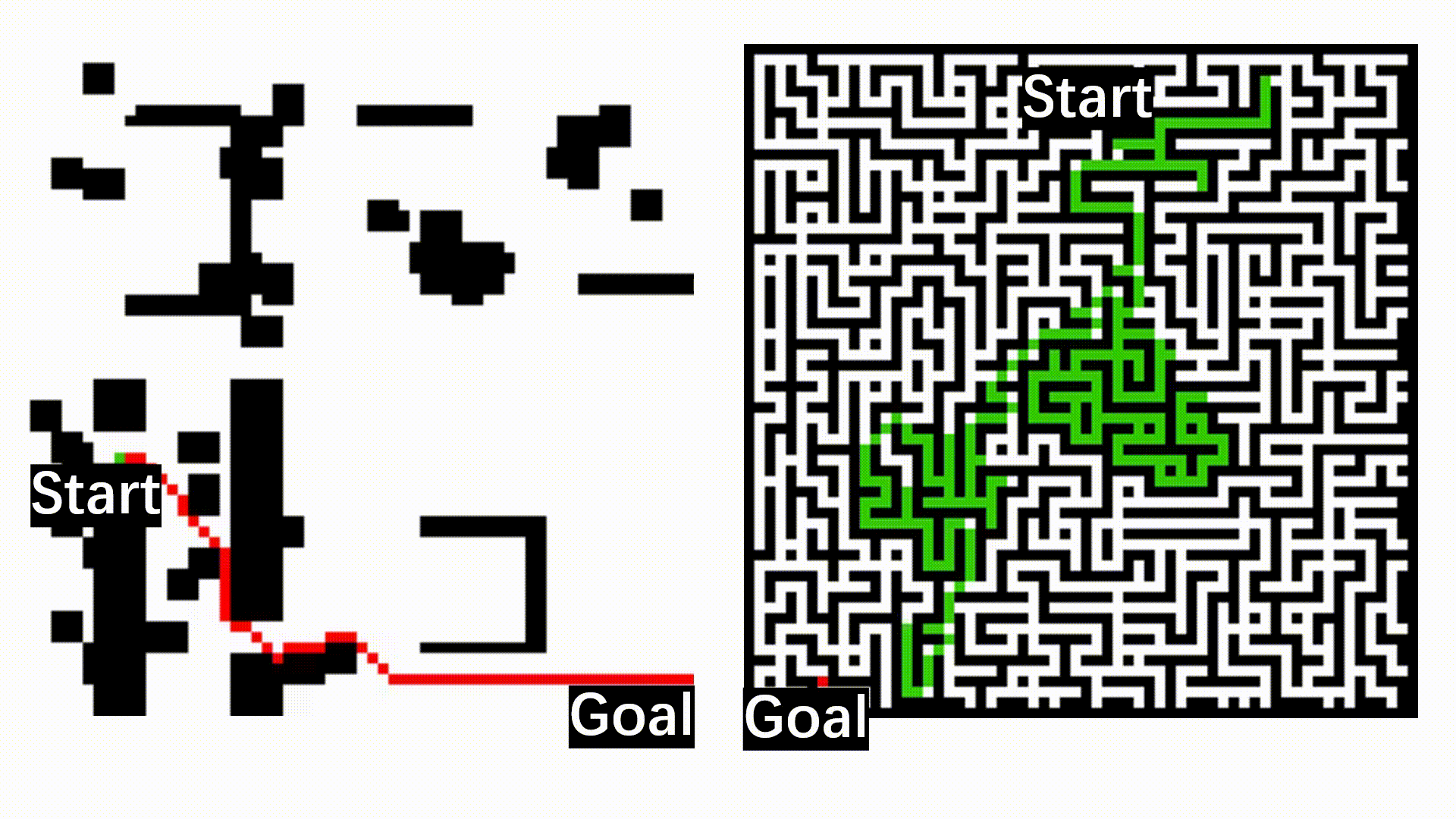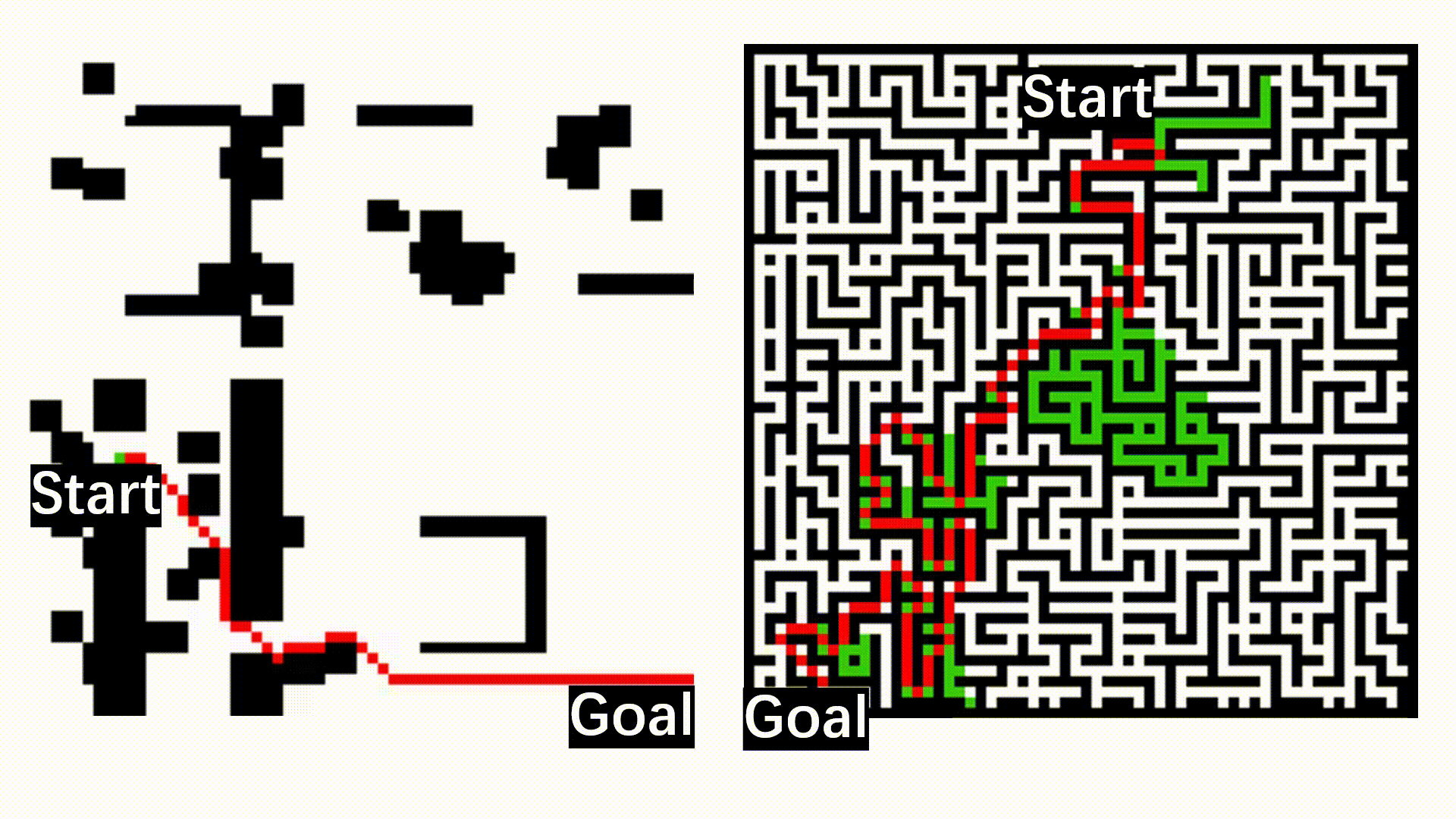
Exploration Behaviors Compared with Frontier-based Method
With learned value function, our OPERE (left) can explore high value regions, while frontier-based method (right) fails.
Publications
-
 Off-Policy Evaluation with Online Adaptation for Robot Exploration in Challenging Environments.IEEE Robotics and Automation Letters (RA-L), vol. 8, no. 6, pp. 3780–3787, 2023.
Off-Policy Evaluation with Online Adaptation for Robot Exploration in Challenging Environments.IEEE Robotics and Automation Letters (RA-L), vol. 8, no. 6, pp. 3780–3787, 2023.