NI-SLAM is a novel visual SLAM method for the warehouse robot with a single downward-facing camera using ground textures. Traditional methods resort to feature matching or point registration for pose optimization, which easily suffers from repetitive features and poor texture quality. In this paper, we present a robust kernel cross-correlator (KCC) for robust image-level registration. Compared with the existing methods that often use iterative solutions, our method, named non-iterative visual SLAM (NI-SLAM), has a closed-form solution with a complexity of O(N log N). This allows it to run very efficiently, yet still provide better accuracy and robustness than the SOTA methods. In the experiments, we demonstrate that it achieves 78% improvement over the SOTA systems for indoor and outdoor localization. We have successfully tested it on warehouse robots equipped with a single downward camera, showcasing its product-ready superiority in a real operating area.
Motivation
When deploying visual SLAM in warehouse robots, numerous hurdles must be overcome. On one hand, in environments like the one showed bellow, where multiple robots collaborate to transport goods within the warehouse, the high dynamism often leads to visual localization errors. On the other hand, warehouses are typically vast, causing static features to be distant from the camera and reducing visual SLAM system accuracy. To address this, we presented NI-SLAM for the warehouse robot using ground textures, which includes non-iterative visual odometry, loop closure detection, and map reuse. Our system can provide robust localization in dynamic and large-scale environments using only a monocular downward-facing camera.

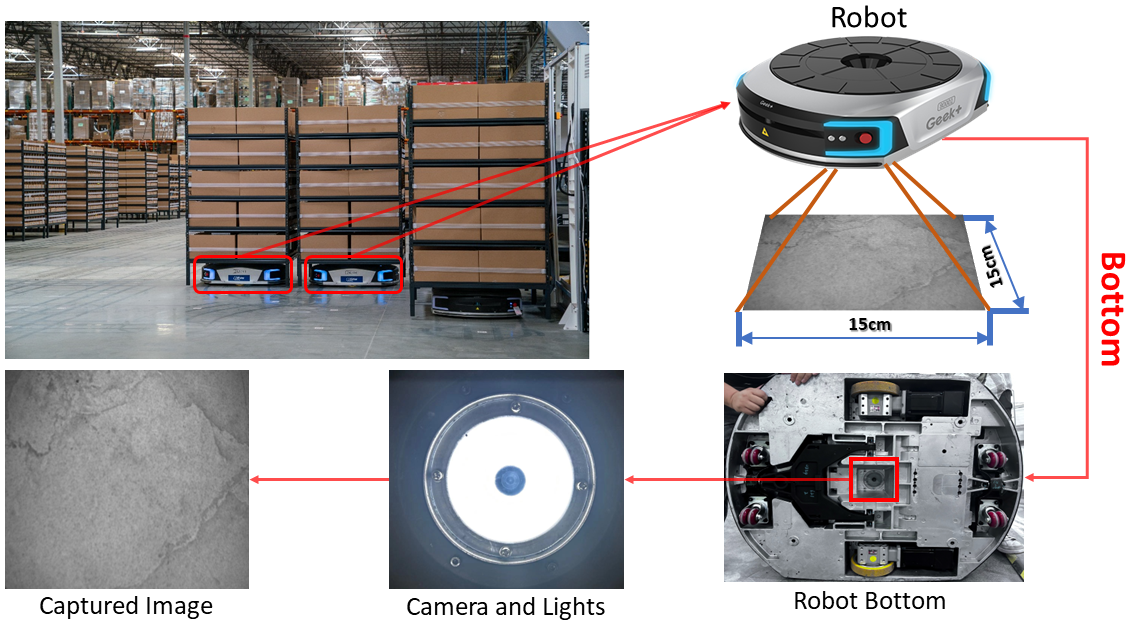
System Design
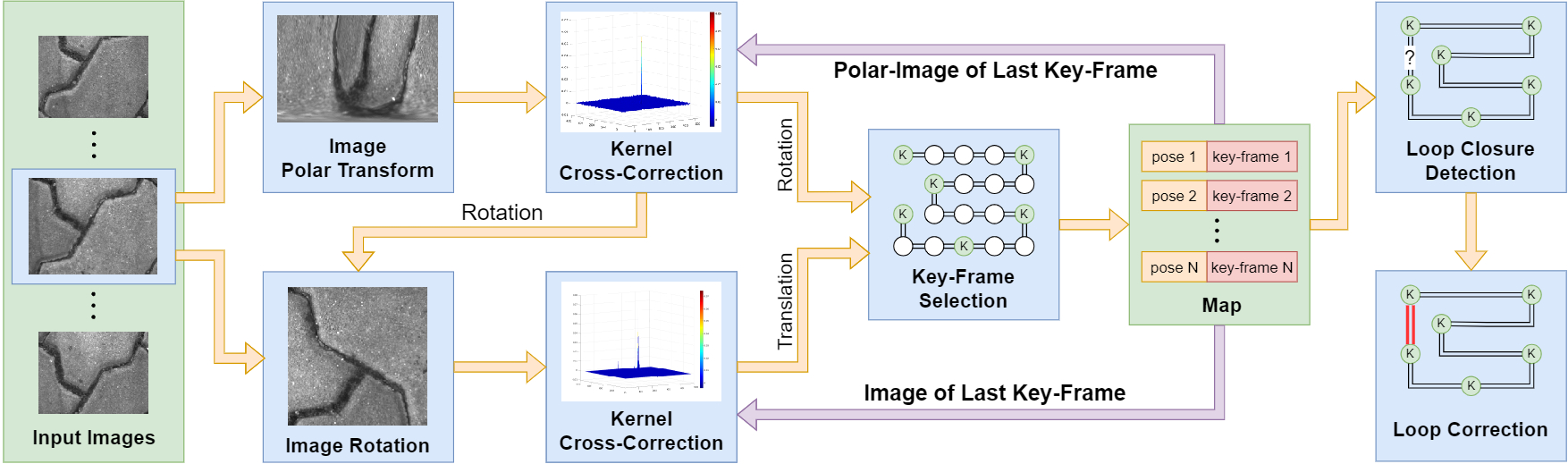
The pipeline of NI-SLAM is showed bellow. Our inputs comprise grayscale images taken by a camera mounted to face downward. The outputs are 3-DOF camera poses, specifically 2-DOF translations and rotation. The entire workflow is simple: The initial frame is designated as the first key-frame; Upon capturing a subsequent frame, the relative motion between the present and the key-frame is determined; Leveraging the estimated relative pose and its confidence, a new key-frame is chosen and integrated into the map; Subsequently, we identify its neighboring key-frames within the map, aiming to pinpoint a loop closure; If a loop closure is detected, we execute a pose graph optimization to minimize the drift error.
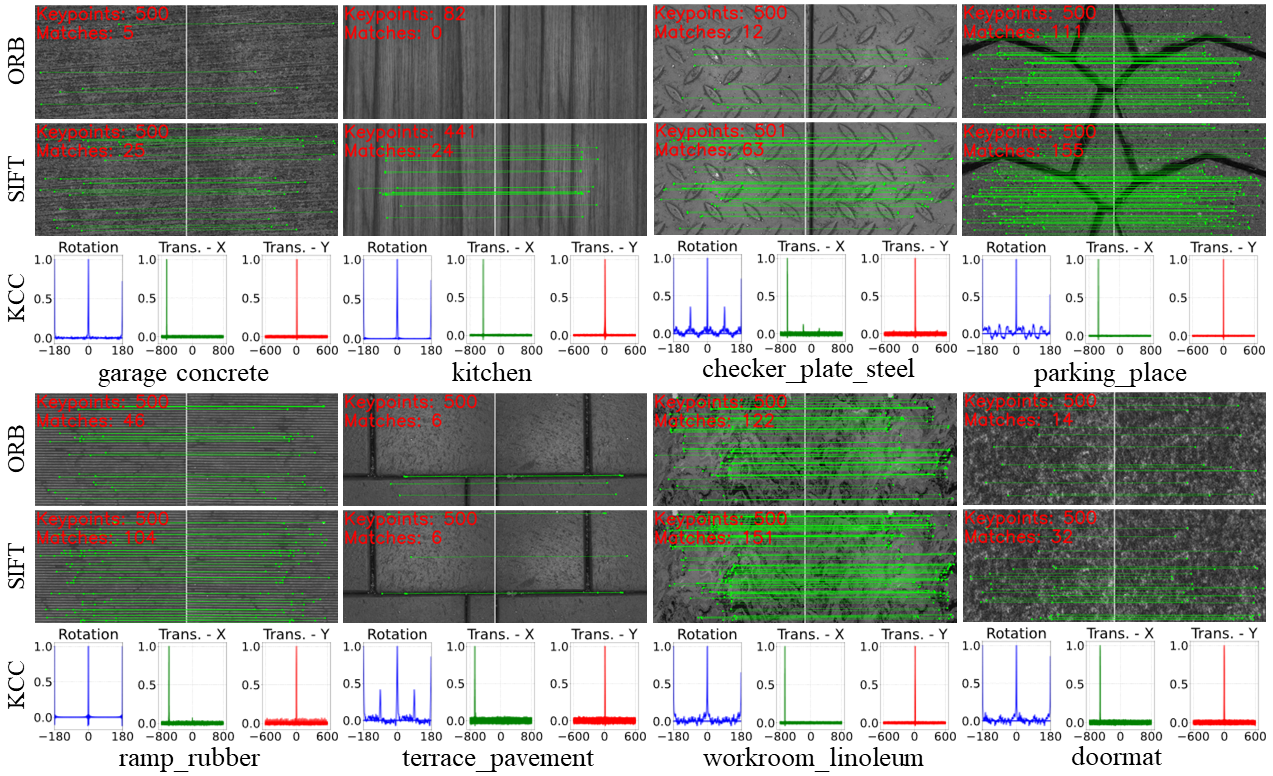
We also present a robust kernel cross-correlator (KCC) for robust image-level registration. Compared with the feature-based methods, KCC can achieve more robust and accurate estimation on the ground with few features or repetitive patterns.
Experiments
The figure below shows the comparison of data association of ORB, SIFT and KCC. Since KCC operates as an image-matching technique, its estimation is graphically represented with the normalized confidence on the vertical axis, while the horizontal axis details the corresponding movements in rotation and translation. It can be seen that KCC consistently demonstrates accuracy and stability across diverse ground textures. This is evident from the distinctly pronounced peaks that tower significantly over other positions. However, the performance of feature-based methods fluctuates. They show commendable results on textures enriched with unique corners, such as in the sequence of “parking place”, and “workroom linoleum”; while struggling to detect a sufficient number of matches in the sequence of “doormat”, “garage concrete”, and “terrace pavement”. On the “kitchen” texture, they fail to even detect an adequate number of features.
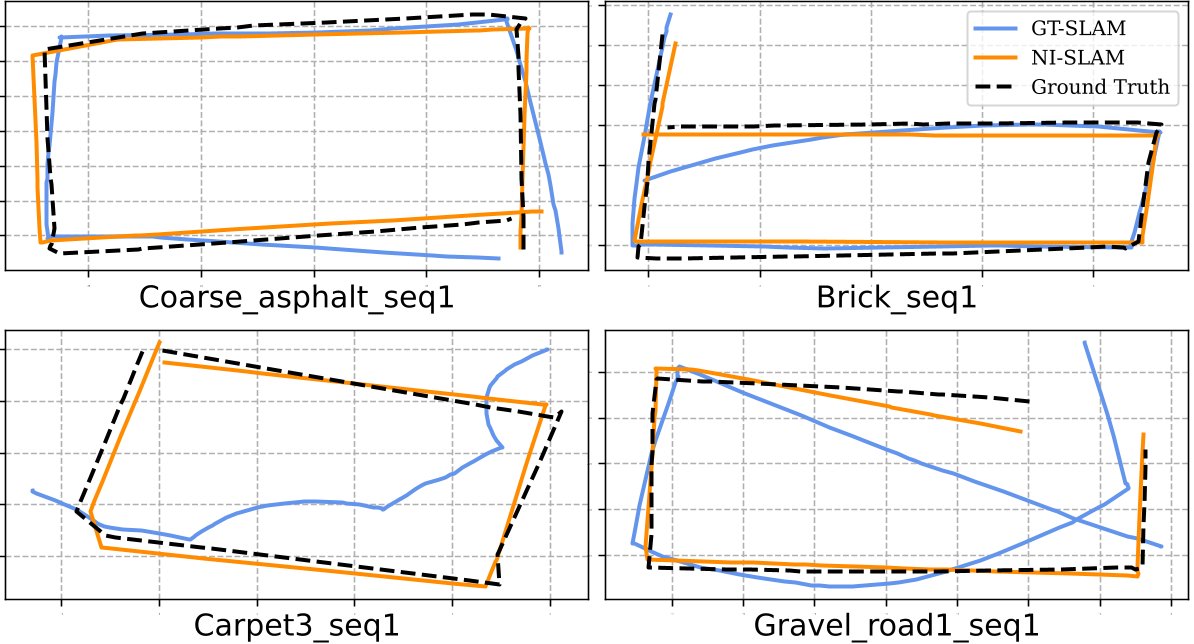
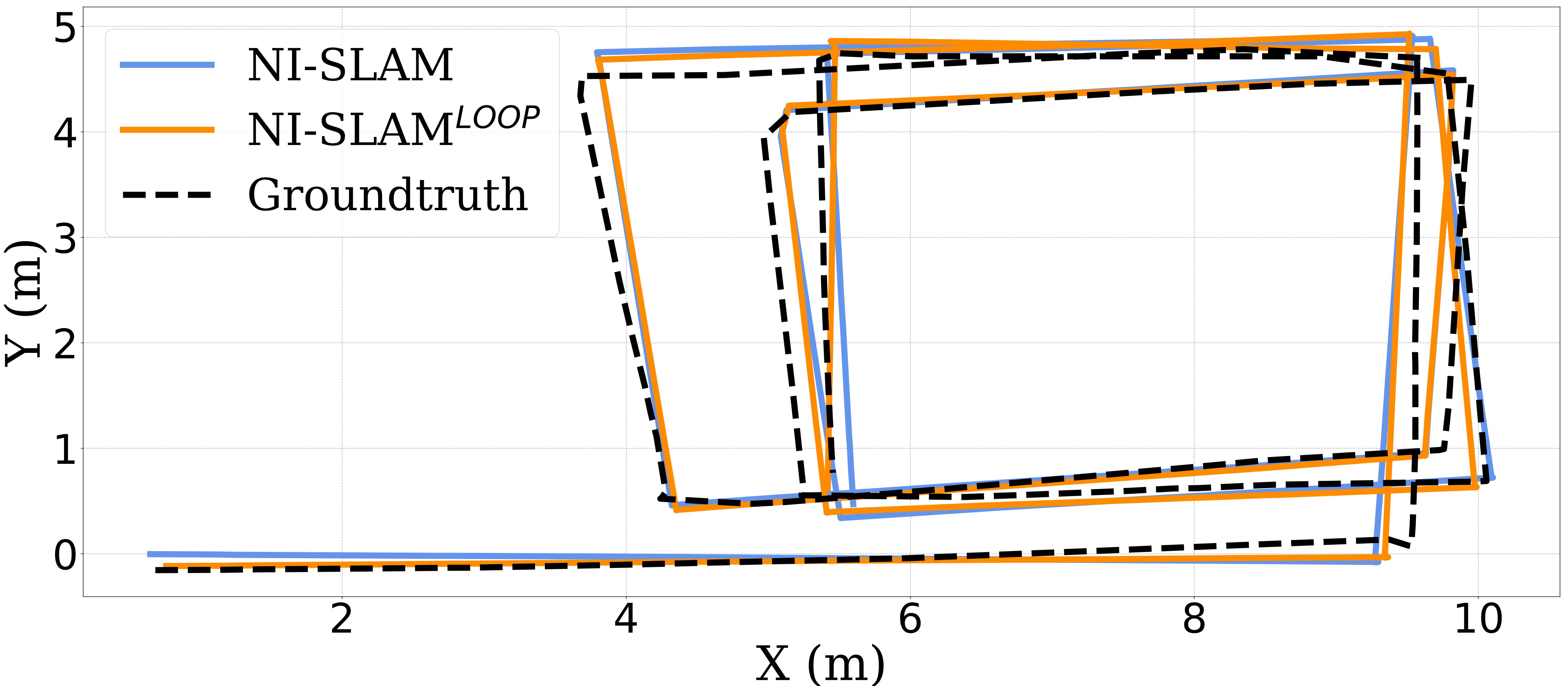
The VO comparison and loop detection experiment are showed below. It can be seen that our system achieve better performance than the SOTA ground-texture-based localization system. Besides, the pose errors are significantly decreased after the loop correction, which shows that the effectiveness of the proposed loop detection method.
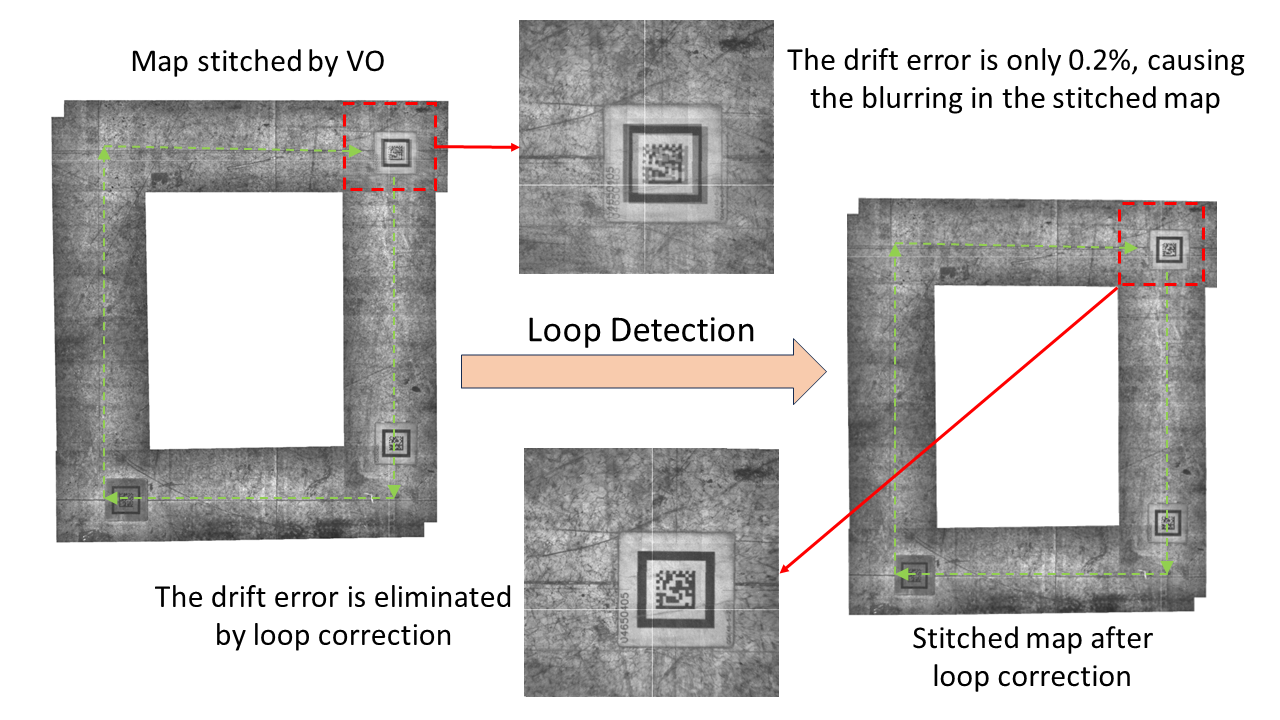
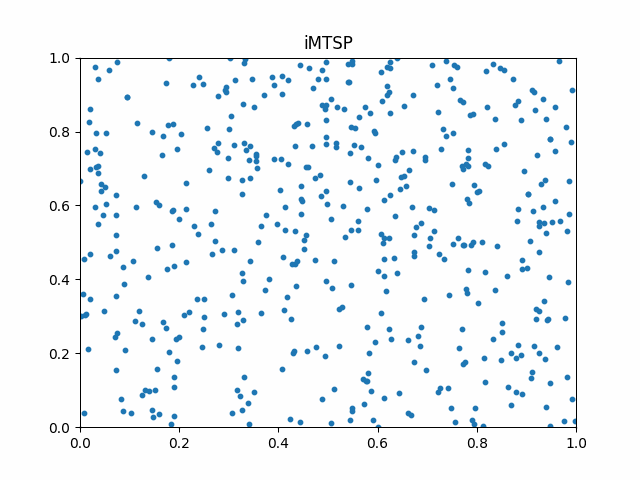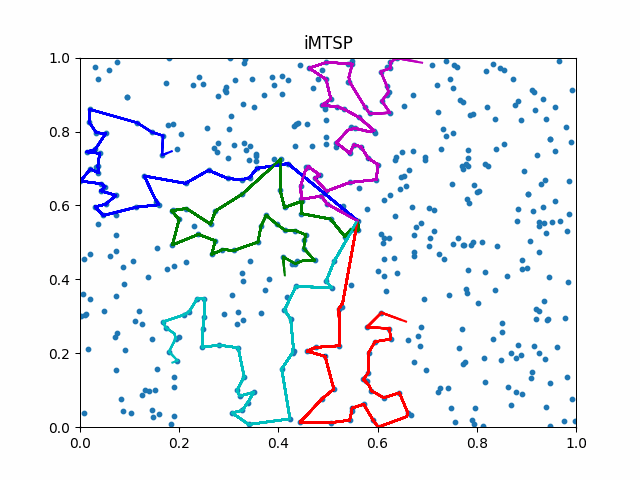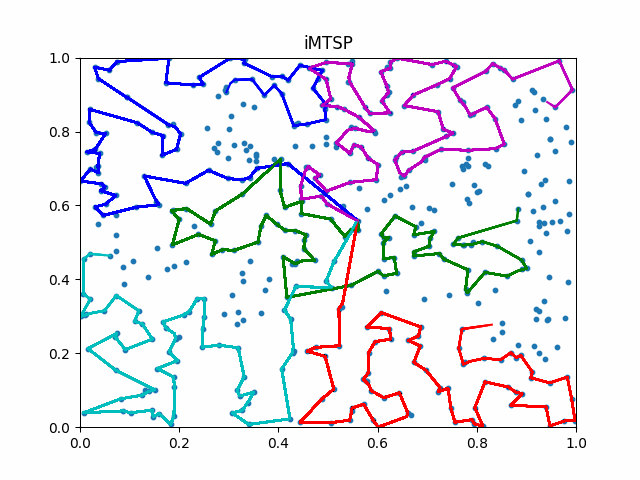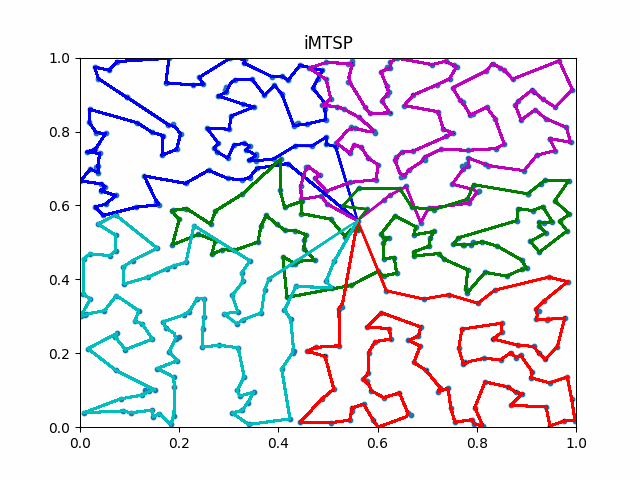
Live Mapping Demo
We showcase a real-time mapping demonstration with loop detection and correction. This data is gathered in a warehouse setting by an Automated Guided Vehicle (AGV). We maneuvered the robot along a rectangular trajectory (highlighted by the green line) to initiate and stop at the identical location (indicated by the red square), effectively creating a loop. Images from this path are then composited using the pose estimates produced by NI-SLAM, both without (on the left) and with (on the right) loop correction. Due to the drift error, the stitched map without loop correction exhibits noticeable blurring, which is eliminated on the right. This clarity underscores the effective elimination of drift errors and the precise pose corrections.