We employ imperative learning for self-supervised path planning.
The problem of path planning has been studied for years. Classic planning pipelines, including perception, mapping, and path searching, can result in latency and compounding errors between modules. While recent studies have demonstrated the effectiveness of end-to-end learning methods in achieving high planning efficiency, these methods often struggle to match the generalization abilities of classic approaches in handling different environments. Moreover, end-to-end training of policies often requires numerous labeled data or training iterations to reach convergence. In this work, we present a novel Imperative Learning (IL) approach.
An overview of the iPlanner framework. The pipeline consists of two parts, forming a bilevel opitmization process with upper-level network update and lower-level trajectory optimization. During inference, the perception and planning network first encodes the depth measurement and goal position to predict a key-point path toward the goal with an associated collision probability. During training, the trajectory cost and task-level "fear" loss are propagated back to provide direct gradients for updating both the perception and planning networks simultaneously.
This approach leverages a differentiable cost map to provide implicit supervision during policy training, eliminating the need for demonstrations or labeled trajectories. Furthermore, the policy training adopts a Bi-Level Optimization (BLO) process, which combines network update and metric-based trajectory optimization, to generate a smooth and collision-free path toward the goal based on a single depth measurement.
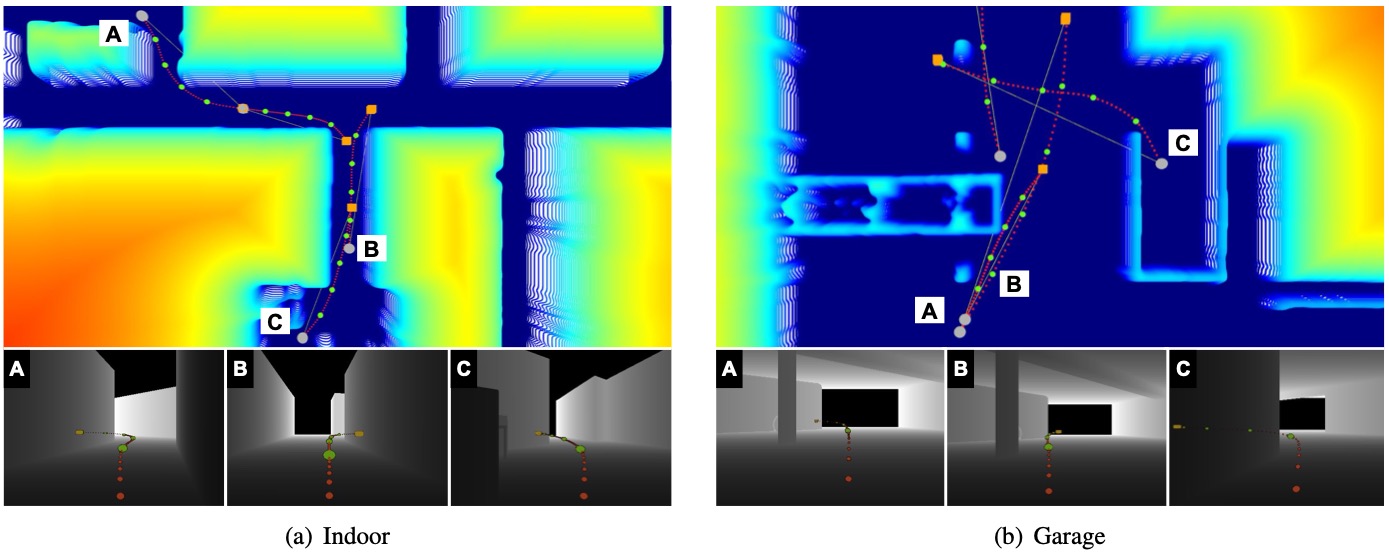
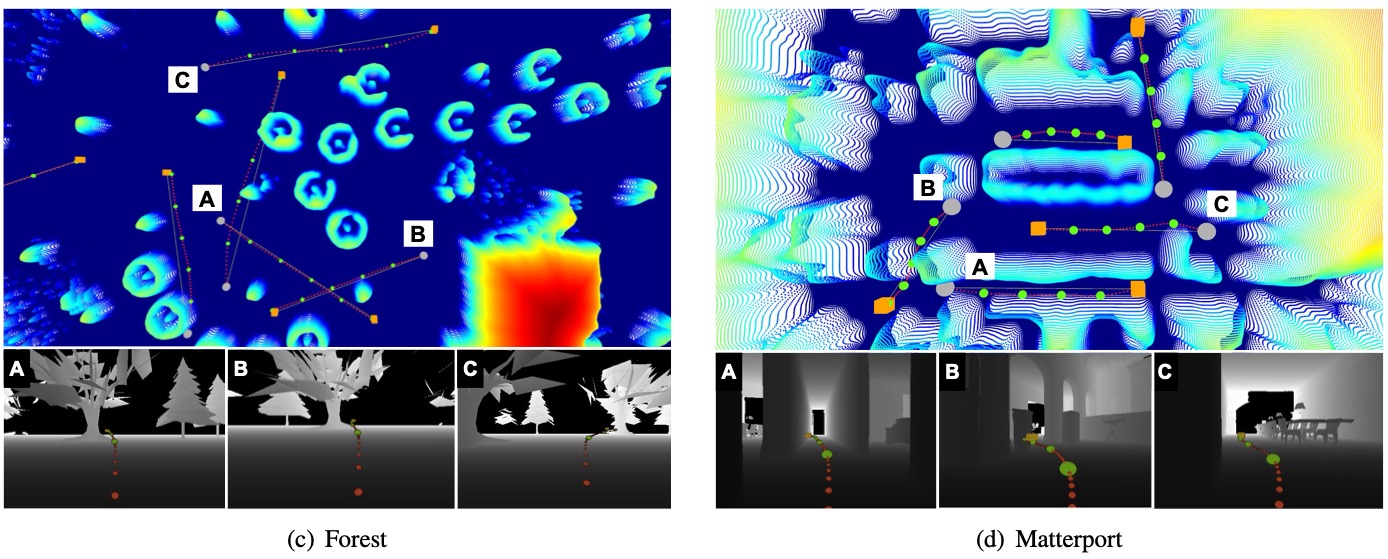
Planning examples in simulation experiments: (a) Indoor, (b) Garage, (c) Forest, (d) Matterport3D. The bottom images show the depth measurements for the corresponding marked trajectories on the cost maps. The key points (green), along with the trajectories (red) shown in the depth images, or on cost maps, are generated by our method from the current robot positions (gray dot) to the goals (yellow/orange box), with the current depth images. The trajectories shown in the depth measurements are projected onto the image frame for visualization purposes.
Experiments
iPlanner allows task-level costs of predicted trajectories to be back-propagated through all components to update the network through direct gradient descent. In our experiments, the method demonstrates around 4x faster planning than the classic approach and robustness against localization noise. Additionally, the IL approach enables the planner to generalize to various unseen environments, resulting in an overall 26-87% improvement in SPL performance compared to baseline learning methods.
Real-world experiment with the legged robot, with the red curve indicating the robot’s trajectory starting from right to left. The robot begins inside a building and navigates to the outside. Green boxes A-F mark different planning events during the route. The robot follows a series of waypoints (shown in blue) and plans in between to: (A) pass through doorways, (B, D, E) circumvent static/dynamic obstacles, and (B, F) ascend and descend stairs.
Simulation
Real-world Experiments
Publications
iPlanner: Imperative Path Planning.
Fan Yang, Chen Wang, Cesar Cadena, Marco Hutter.
Robotics: Science and Systems (RSS), 2023.
Highlighted as an iSeries Article in Visual Planning
@inproceedings{yang2023iplanner,
author = {Yang, Fan and Wang, Chen and Cadena, Cesar and Hutter, Marco},
title = {{iPlanner}: Imperative Path Planning},
booktitle = {Robotics: Science and Systems (RSS)},
url = {https://arxiv.org/abs/2302.11434},
code = {https://github.com/sair-lab/iPlanner},
year = {2023},
website = {https://sairlab.org/iPlanner/},
addendum = {Highlighted as an iSeries Article in Visual Planning}
}
Yang, Fan and Wang, Chen and Cadena, Cesar and Hutter, Marco, "iPlanner: Imperative Path Planning," Robotics: Science and Systems (RSS), 2023.