AirVO is an illumination-robust and accurate stereo visual odometry system based on point and line features. To be robust to illumination variation, we introduce the learning-based feature extraction and matching method and design a novel VO pipeline, including feature tracking, triangulation, key-frame selection, and graph optimization etc. We also employ long line features in the environment to improve the accuracy of the system.
Different from the traditional line processing pipelines in visual odometry systems, we propose an illumination-robust line tracking method, where point feature tracking and distribution of point and line features are utilized to match lines. By accelerating the feature extraction and matching network using Nvidia TensorRT Toolkit, AirVO can run in real time on GPU.
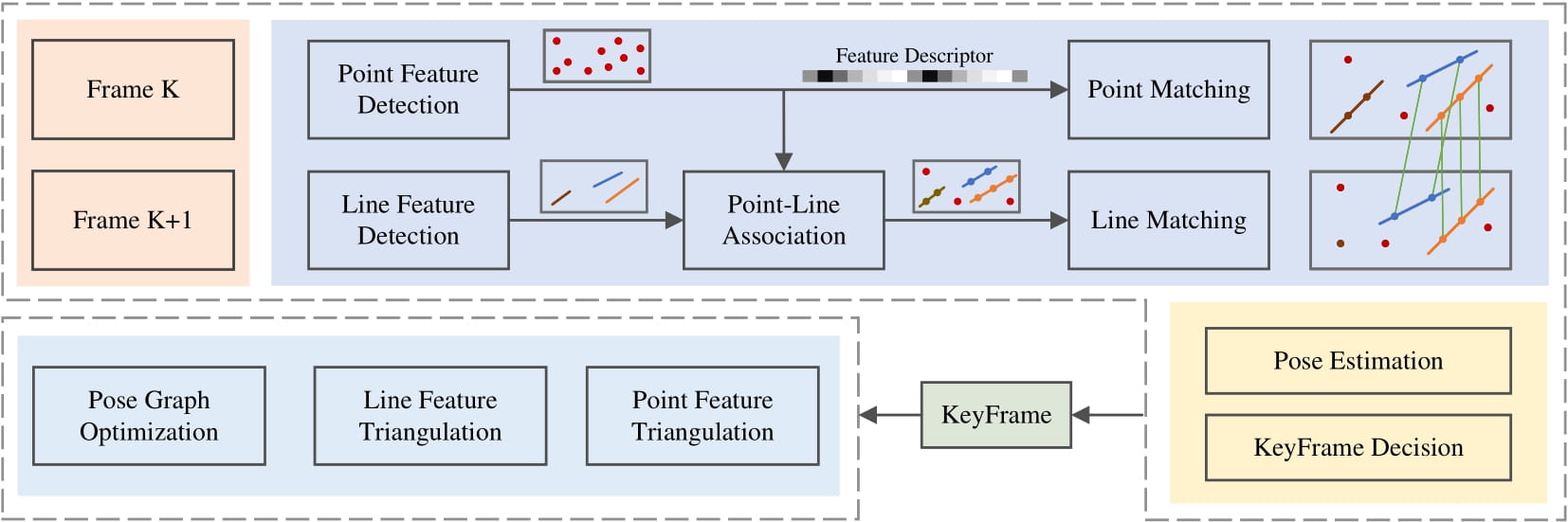
The proposed framework is shown in Figure 1. It’s a hybrid VO system where we utilize both a learning-based frontend and a traditional optimization backend. For every stereo image pair, we first employ a CNN (e.g., SuperPoint) to extract feature points and match them with a feature matching network (e.g., SuperGlue).


Line features are also utilized in our system to improve accuracy. Observing that many key points extracted in our system lie on edges, where line features are detected, the two kinds of features are associated according to their distances. Then lines on stereo images or different frames can be matched or tracked using the matching results of their associated points for better illumination robustness. To improve the system efficiency, we only perform feature tracking on left images for different frames. Based on the feature tracking result, we select key-frames and optimize points, lines, and these key-frames with bundle adjustment.
AirVO can provide accurate localization in dynamic illumination environments. We perform experiments on two challenging datasets: UMA-VI dataset and OIVIO dataset. UMA-VI dataset contains many sequences where images may suddenly darken as a result of turning off the lights, while OIVIO dataset collects data in mines and tunnels with onboard illumination.
Video
Publications
-
AirVO: An Illumination-Robust Point-Line Visual Odometry.IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 3429–3436, 2023.