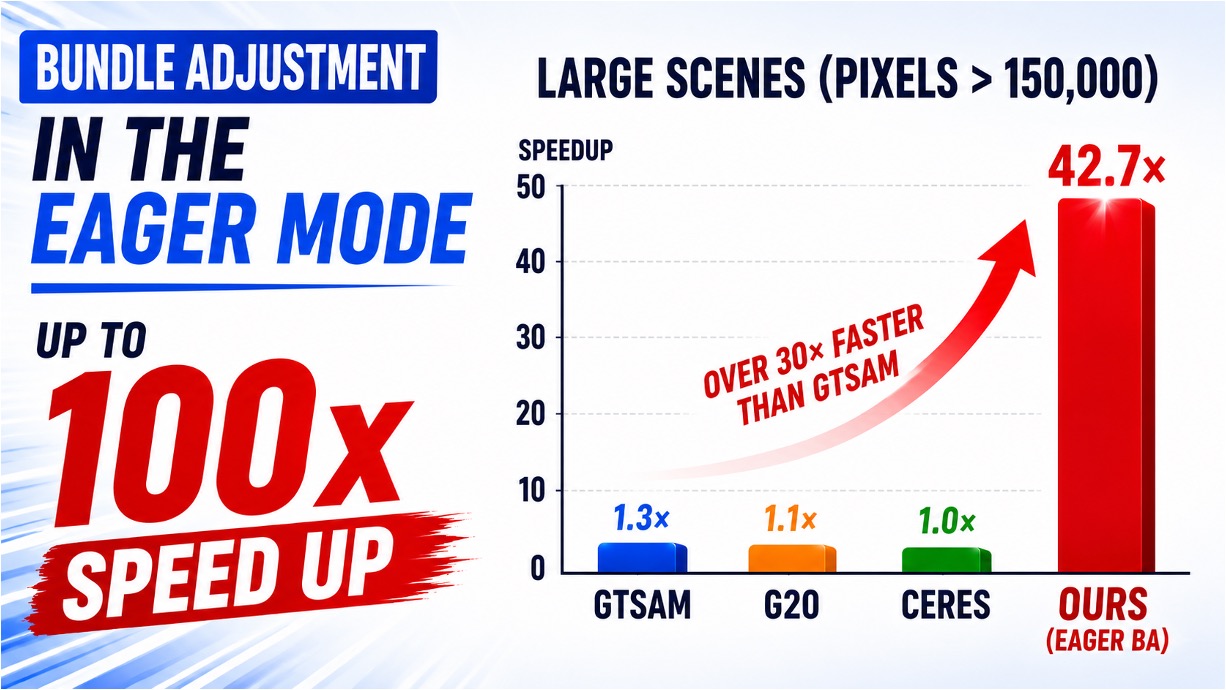
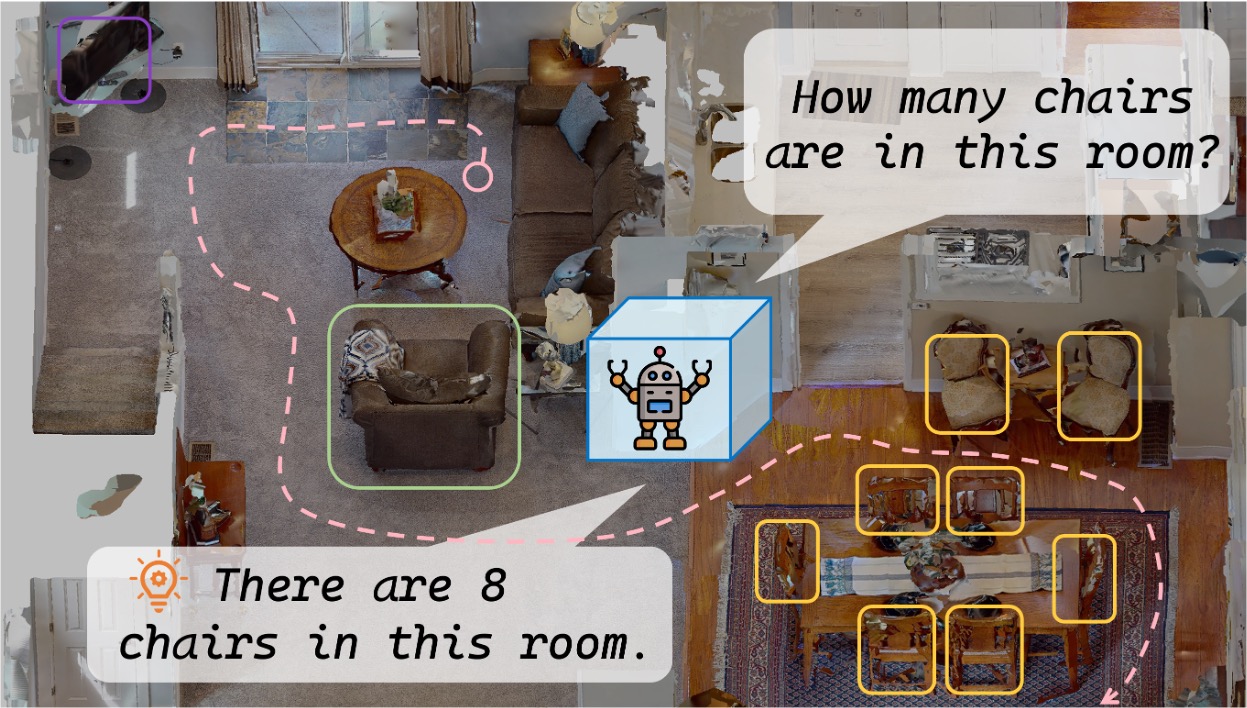
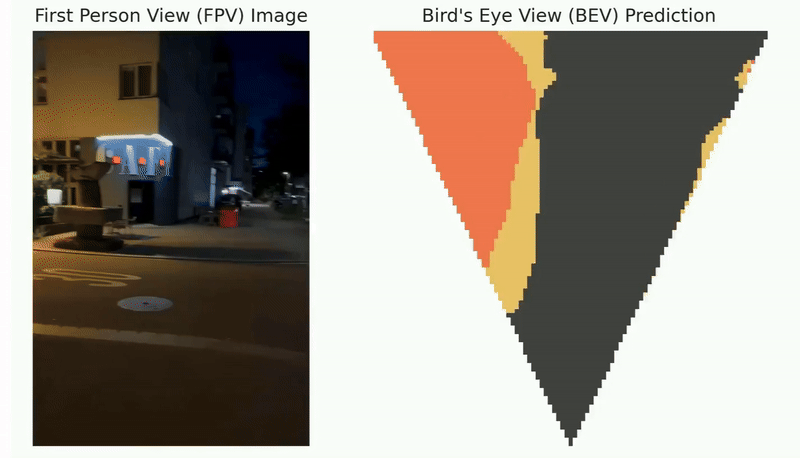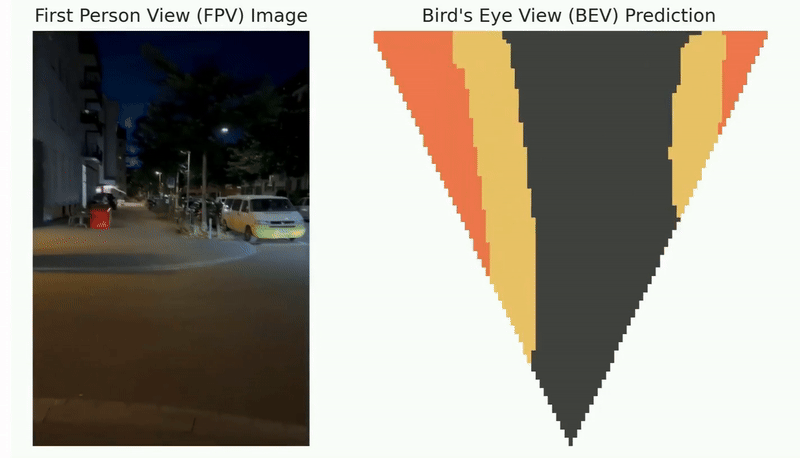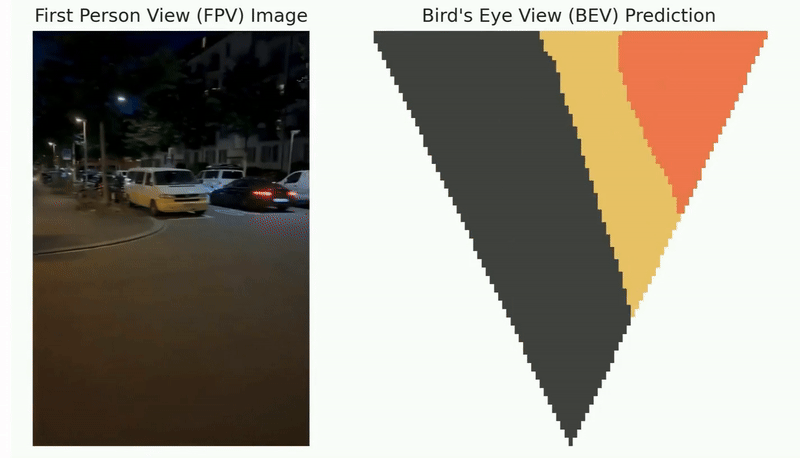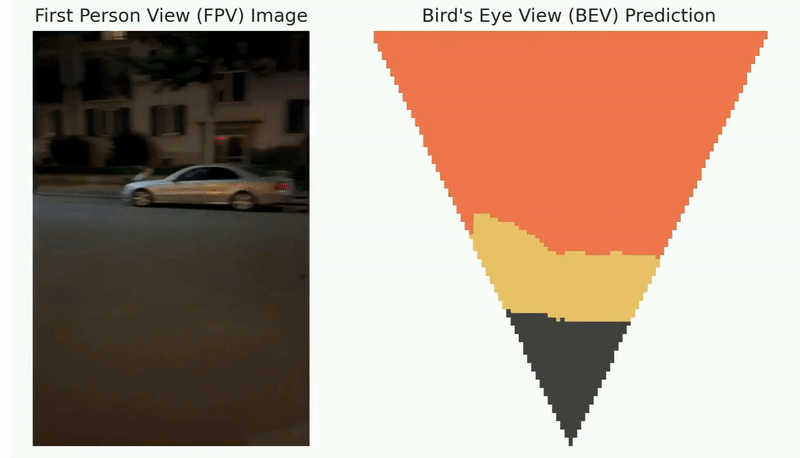
After deployment to the wild, the robot may benefit if it can incrementally learn from the working environments with newly observed data. However, as the perception algorithm involves more and more deep networks for improved robustness over traditional methods, this becomes hard: Deep models typically need to adjust all parameters jointly to adapt to new environments.
This poses a dilemma: On the one hand, if we only retrain on the data increments, fitting to the new data almost inevitably alters the parameters and, subsequently, the representations learned from the old data, leading to performance degradation over time. This phenomenon is referred to as catastrophic forgetting. On the other hand, if all previously observed data is retained to perform joint training after observing each new environment, the storage cost will grow linearly as the model learns from one environment to the next. This is prohibitive on resource-constrained devices such as a drone’s onboard computer.
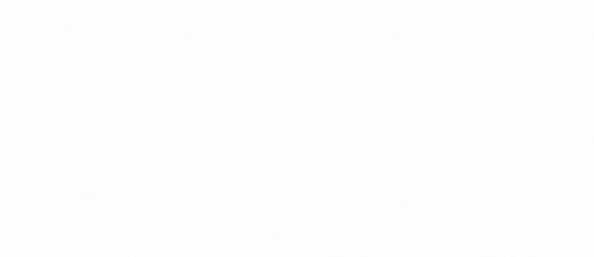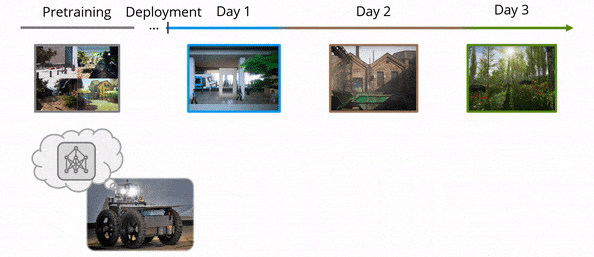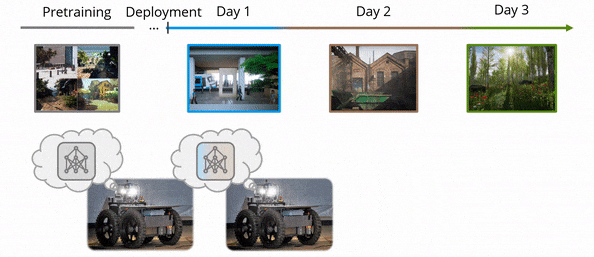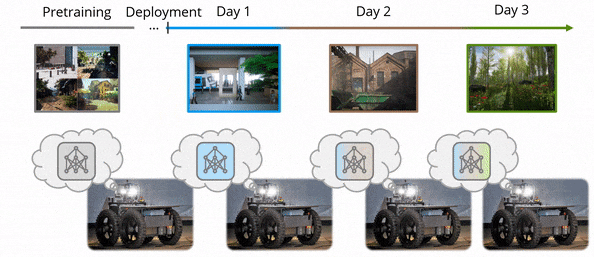
Lifelong loop closure detection
In this work, we focus on the specific problem of learning a loop closure detection (LCD) network in an incremental fashion. We developed AirLoop, a method that leverages techniques from lifelong learning to minimize forgetting when training loop closure detection models incrementally. To the best of our knowledge, AirLoop is one of the first work to study LCD in the lifelong learning context.
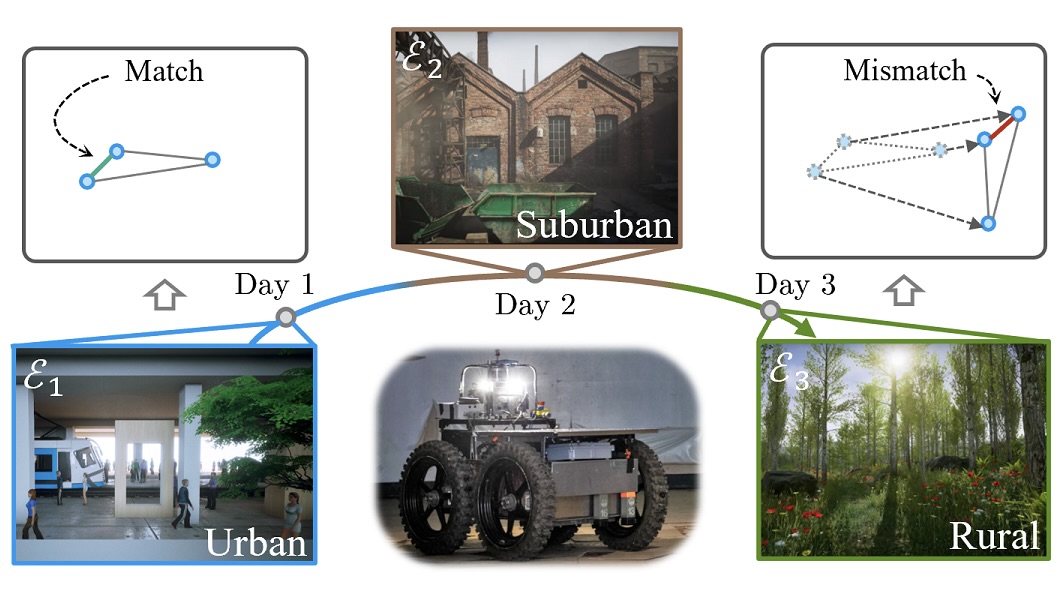
To achieve lifelong learning of LCD models, it is important to ensure that the geometry of the global descriptor space (i.e. descriptors’ pairwise similarities) does not deform as the network trains in more environments. For this purpose, we adopted the relational variant of two regularization losses for lifelong classification, dubbed RMAS (relational memory aware synapses) and RKD (relational knowledge distillation). The former operates by calculating the descriptor space’s “sensitivity” with respect to each parameter and use it to selectively penalize future changes to the parameters, whereas the later compare the output of the current network against its previous versions and protects the descriptor space from uncontrolled deformation.

Both method combined allows us to train the LCD model in a series of environments sequentially without suffering from serious catastrophic forgetting while only requiring constant memory and computation.
Results
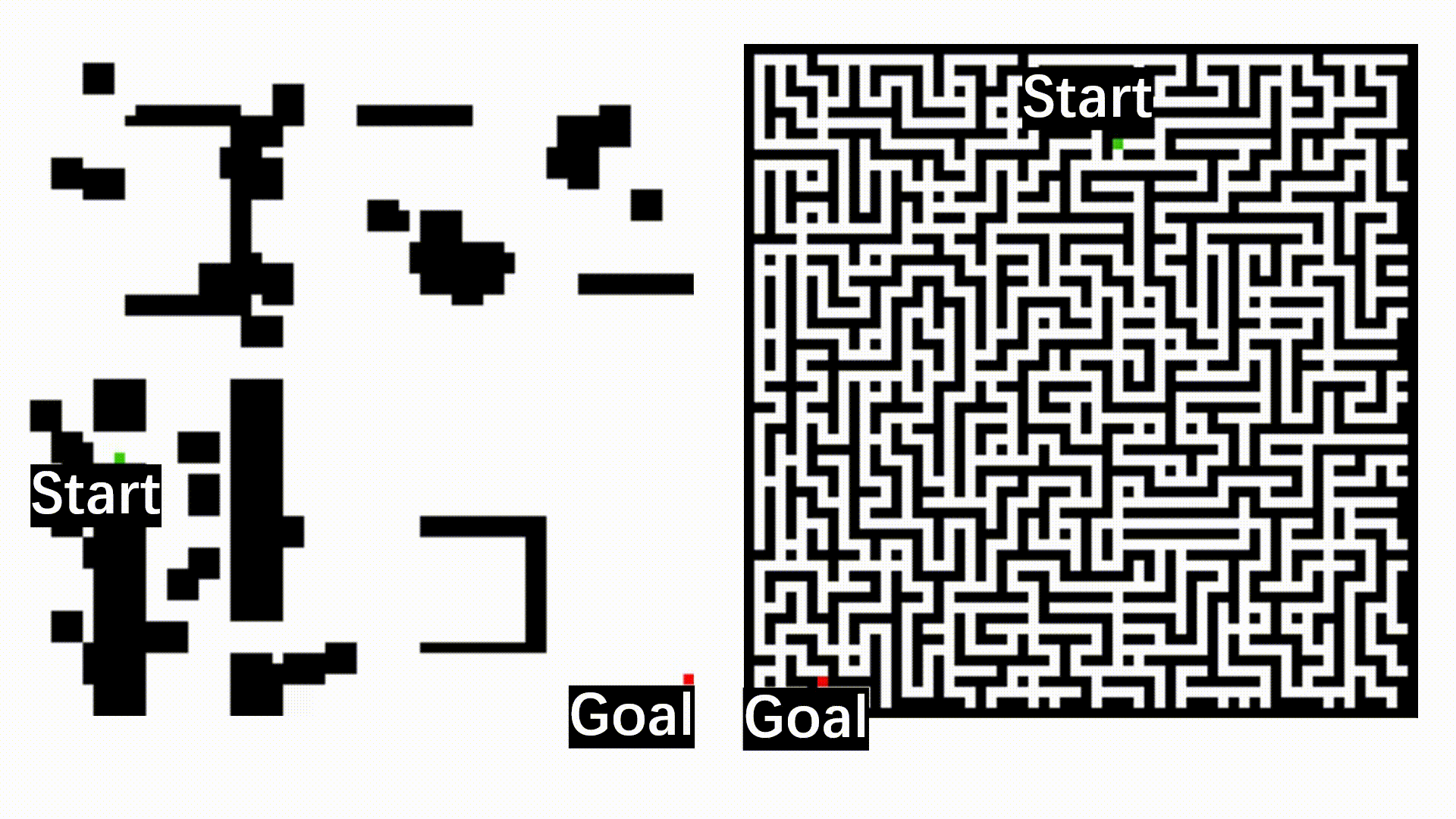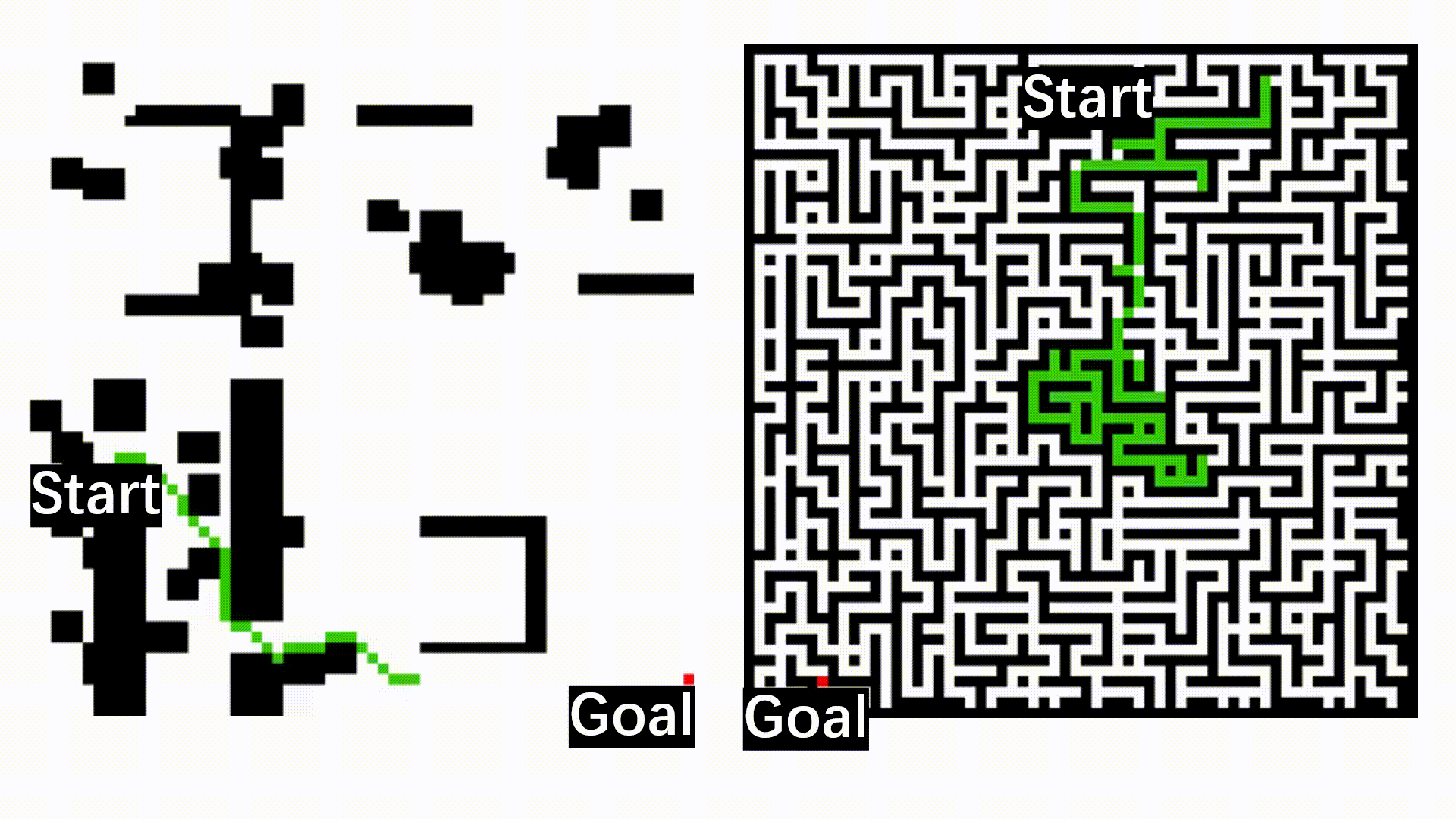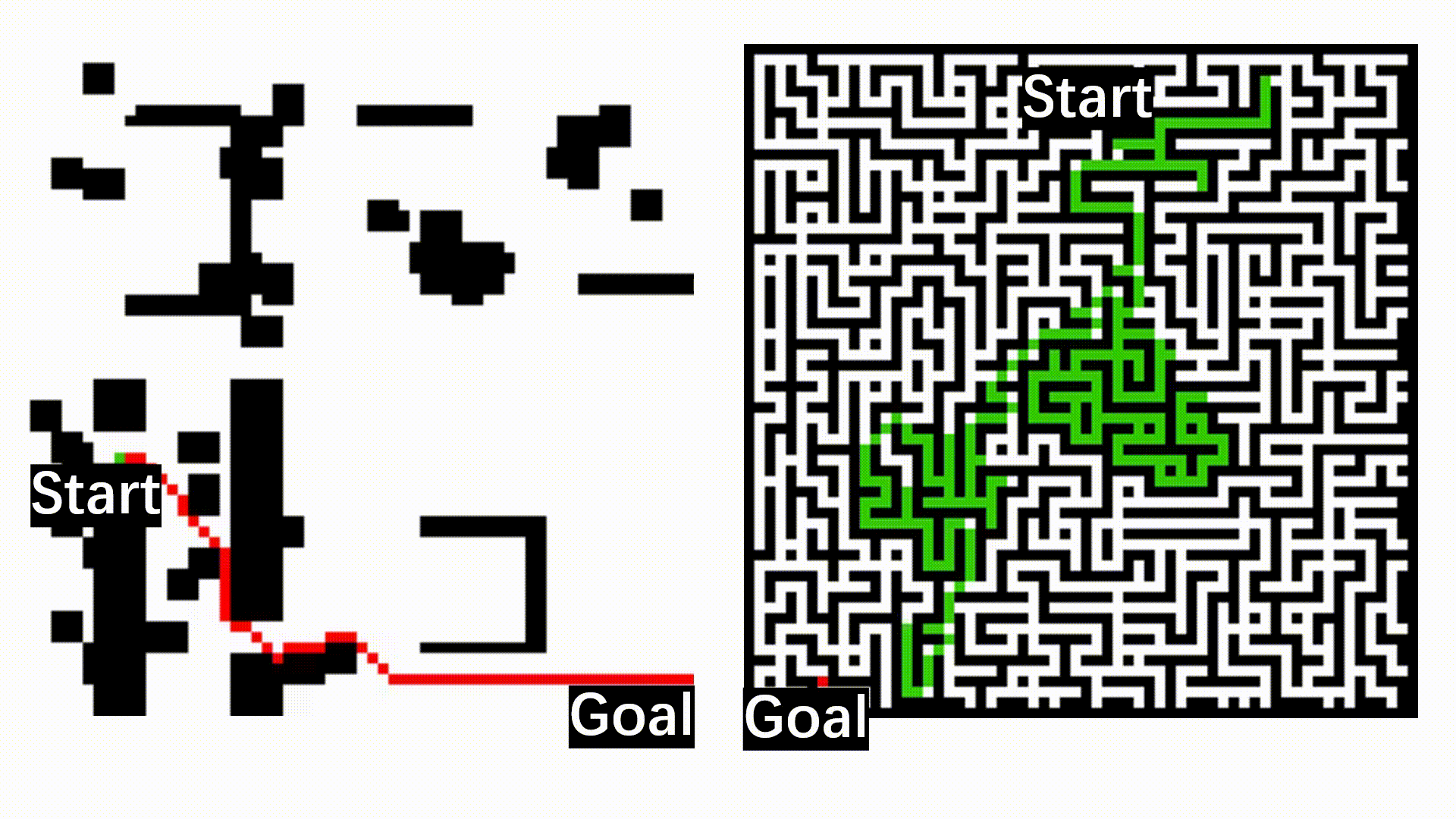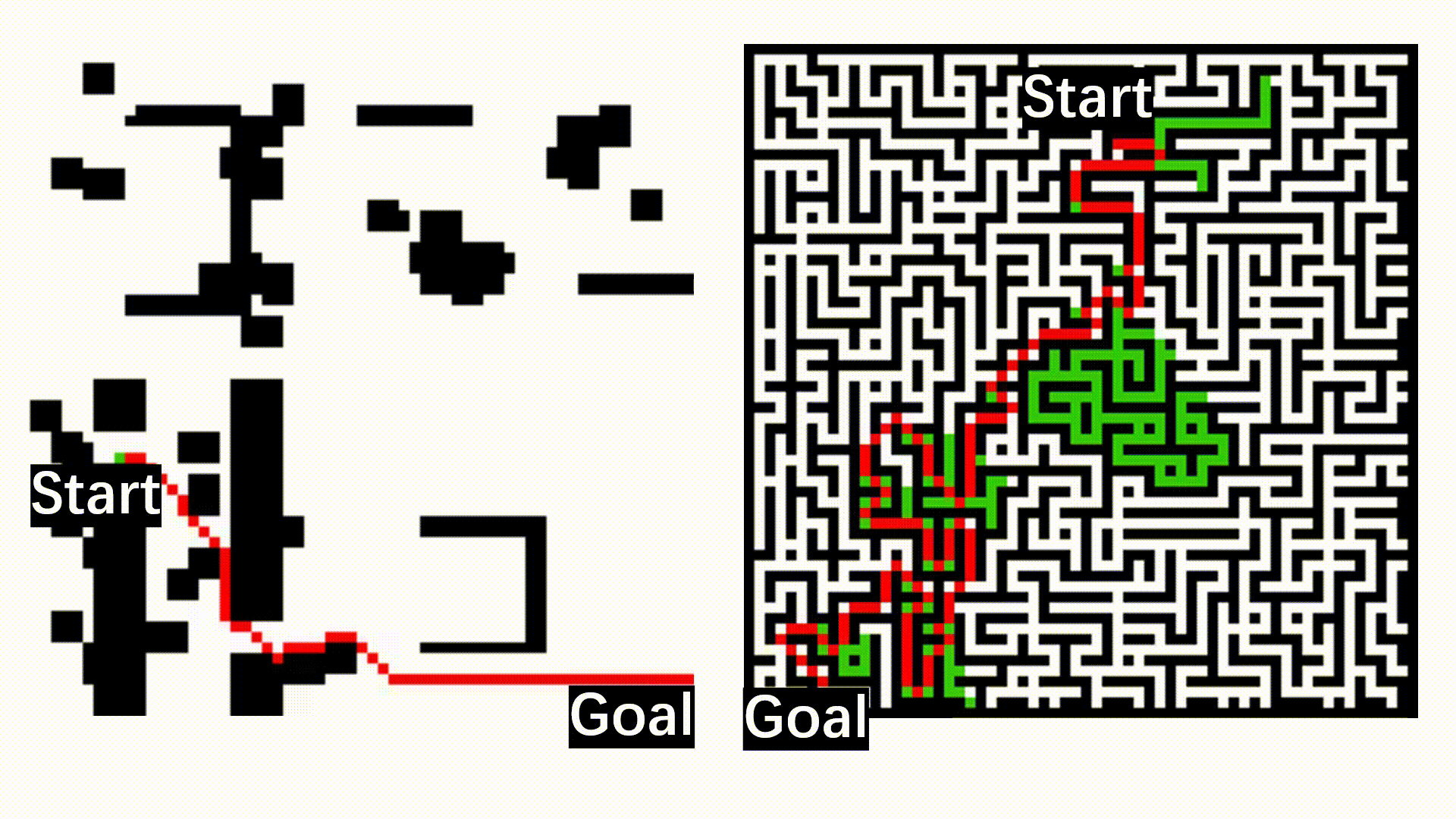
Here we show the lifelong learning outcome of the model on TartanAir, Nordland, and RobotCar:

We also observe improved robustness after extended training:

Video
Publications
-
 AirLoop: Lifelong Loop Closure Detection.International Conference on Robotics and Automation (ICRA), pp. 10664–10671, 2022.
AirLoop: Lifelong Loop Closure Detection.International Conference on Robotics and Automation (ICRA), pp. 10664–10671, 2022.